
데이터분석 공부/Python
[Python] Pandas - ①
JEONGHEON
2022. 1. 24. 14:30
오늘은 말씀드린 대로 NumPy에 이어서 Pandas 라이브러리에 대해 알아보겠습니다!
Pandas 라이브러리는 대표적인 데이터 분석 라이브러리이며
행과 열로 이루어진 데이터 객체를 만들고 다룰 수 있어
안정적으로 대용량의 데이터를 처리하는 데 매우 편리하다는 장점이 있습니다.
이번에도 마찬가지로 주피터 노트북을 이용했으며 이용하고 싶으시다면
2022.01.22 - [데이터 분석 공부하기/Python] - [Python] Jupyter Notebook 설치 및 실행
[Python] Jupyter Notebook 설치 및 실행
오늘은 간단하게 Anaconda를 설치하여 주피터 노트북을 실행시키는 방법을 알아볼게요! 우선 아나콘다는 수학과 과학 분야에서 사용되는 여러 패키지들을 묶어 놓은 파이썬 배포판이고 대표적으
tnqkrdmssjan.tistory.com
^^^^
여기를 눌러주시면 됩니다!
그럼 시작해 볼까요?
import pandas as pd # Pandas 불러오기
import numpy as np # NumPy 불러오기
1. NumPy를 사용한 데이터 프레임 생성
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
df = pd.DataFrame(data, columns = ['A','B','C'])
df
1-2. dictionary를 사용한 데이터 프레임 생성
data = {
"Name": ['Kim', 'Choi', 'Lee', 'Park', 'Kim', 'Shin'],
"Age": [15, 19, 17, 18, 17, 16],
"Score": [90.5, 78.0, 92.0, 86.5, 90.0, 83.5]
}
df = pd.DataFrame(data, index = ['one', 'two', 'three', 'four', 'five', 'six'])
df
2. 데이터 확인
df.head() # default : 5df.tail(2)df.index # 행 index 출력
>>> Index(['one', 'two', 'three', 'four', 'five', 'six'], dtype='object')df.columns # 칼럼명 출력
>>> Index(['Name', 'Age', 'Score'], dtype='object')df.values # 값 출력
>>> array([['Kim', 15, 90.5],
['Choi', 19, 78.0],
['Lee', 17, 92.0],
['Park', 18, 86.5],
['Kim', 17, 90.0],
['Shin', 16, 83.5]], dtype=object)df.info() # 요약 정보 출력
>>> <class 'pandas.core.frame.DataFrame'>
Index: 6 entries, one to six
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 6 non-null object
1 Age 6 non-null int64
2 Score 6 non-null float64
dtypes: float64(1), int64(1), object(1)
memory usage: 192.0+ bytesdf.describe() # 데이터프레임 열의 간단한 통계 값 출력
3-1. 특정 column의 값만 추출
df['Score'] # 또는 df.Score
>>> one 90.5
two 78.0
three 92.0
four 86.5
five 90.0
six 83.5
Name: Score, dtype: float64
df[['Name', 'Score']]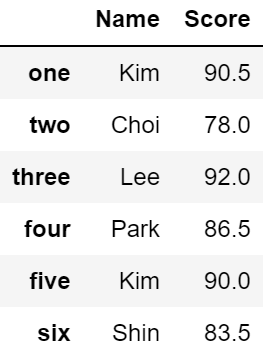
3-2. 특정 행 범위의 값만 추출
df[0 : 3] # df[시작인데스 : 끝인덱스 + 1]
3-3. 이름을 이용하여 추출 : .loc
df.loc['one'] # 'one' 인덱스에 해당하는 모든 칼럼 값 추출
>>> Name Kim
Age 15
Score 90.5
Name: one, dtype: objectdf.loc[:, ['Name', 'Score']]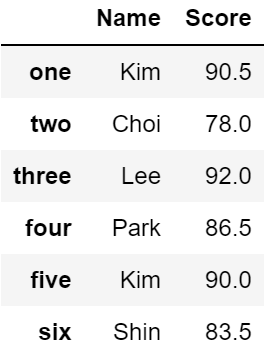
df.loc['two':'five', ['Age', 'Score']]
3-4. 위치를 이용하여 추출 : .iloc
df.iloc[3] # 첫 번째 인덱스 번호는 0
>>> Name Park
Age 18
Score 86.5
Name: four, dtype: objecdf.iloc[2:4, 0:2] # 세 번째, 네 번째 행과 첫 번째, 두 번째 열 추출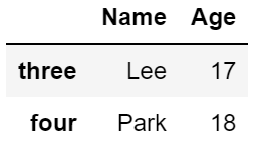
df.iloc[[0, 2, 4], [0, 2]]
df.iloc[1:3, :]
df.iloc[:, 1:3]
3-5. 조건을 이용하여 추출
df[df['Score'] >= 90]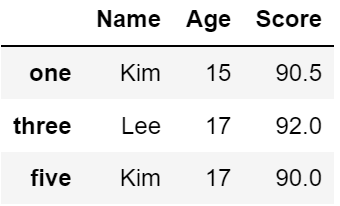
df.loc[df['Name'] == "Kim", ['Name', 'Age']]
df.loc[df['Name'].isin(['Park', 'Kim']), :]
df.loc[(df['Age'] > 16) & (df['Score'] > 90), :] # & : and , | : or
4-1. 값 변경
df.loc['one', 'Age'] = 18
df
4-2. 열 추가
df['Score2'] = [70.5, np.nan, 85.0, 78.5, np.nan, 82.5]
df
df['diff_score'] = df['Score'] - df['Score2'] # 파생변수 생성
df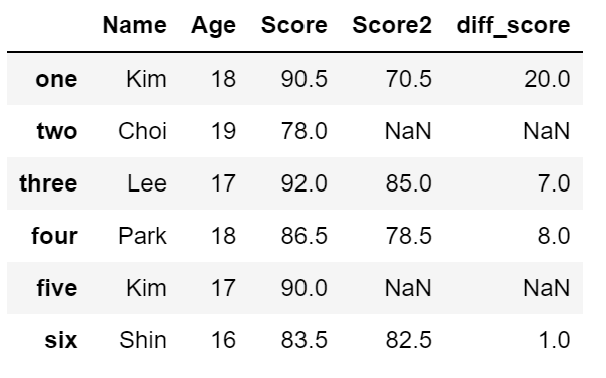
4-3. 열 삭제
df2 = df.copy() # 데이터프레임 복사
del df2['diff_score'] # 해당 열 삭제
df2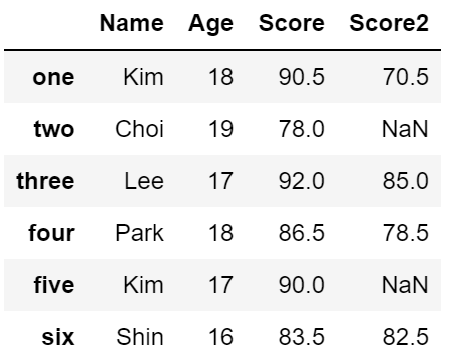
# 또는
df2.drop('Score2', axis = 1) # 기본적으로 저장 X
drop 함수는 특정 행 또는 열을 drop 한 데이터 프레임을 반환하므로 기존의 데이터 프레임에는 영향을 미치지 않는다. 즉, 기존의 데이터 프레임이 변경되도록 하려면 inplace = True 인자를 추가해야 한다.
4-4. 행 추가
new_data = {'Name': 'Lee', 'Age': 17, 'Score': 88.5}
df2.append(new_data, ignore_index = True) # 기본적으로 저장 X
4-5. 행 삭제
df2.drop(['one', 'two']) # 기본적으로 저장 X
Pandas 라이브러리는 2개로 나눠서 진행하겠습니다.
그럼 2편에서 만나요~
