
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- ML
- 이것이 코딩테스트다
- 데이터 전처리
- pandas
- SQLD
- ADsP
- 회귀분석
- IRIS
- scikit learn
- 통계
- 데이터 분석
- matplotlib
- pytorch
- 데이터분석준전문가
- 코딩테스트
- 머신러닝
- Python
- 시각화
- 자격증
- sklearn
- 이코테
- 딥러닝
- SQL
- tableau
- 파이썬
- r
- 태블로
- Deep Learning Specialization
- Google ML Bootcamp
- 데이터분석
- Today
- Total
함께하는 데이터 분석
[Find-A] ELECTRA SpanBERT 본문
ELECTRA의 생성자와 판별자 이해하기
생성자
- MLM 태스크 수행
- 15% 확률로 전체 토큰을 마스크 된 토큰으로 교체, 생성기에서 마스크 된 토큰을 예측하도록 학습 진행
입력 토큰이 X=[x1, x2, ... xn] 일 때 h_G(X)=[h1, h2, ... hn]을 생성기를 통해 얻은 각 토큰의 표현
이제 마스킹한 토큰에 대한 표현을 소프트맥스 함수를 갖고있는 피드포워드 네트워크 분류기에 입력 후 토큰에 대한 확률분포 결과를 얻음

'The chef cooked the meal'이라는 문장을 입력하고 일부 토큰에 대해 마스킹 작업을 수행한 후 생성기에 입력하면, 생성기는 사전에 있는 각 단어의 확률 결과를 출력
xt를 t 위치의 마스크된마스크 된 단어라고 하면, 생성자는 소프트맥스 함수를 적용해 사전의 각 단어가 마스크 된 단어일 확률을 출력

e()는 토큰 임베딩, 생성자에서 출력한 확률 분포를 통해 가장 확률이 높은 단어를 마스킹한 토큰으로 선택
판별자
- 주어진 토큰이 생성자에 의해 만들어진 토큰인지 아니면 원래 토큰인지를 판별하는 것
판별자를 통해 얻은 토큰별 표현을 h_D(X)=[h1, h2, ... hn]
다음으로 각 토큰의 표현을 시그모이드 함수를 가지고 있는 피드포워드 네트워크 형태의 분류기에 입력해 주어진 토큰이 원래 토큰인지 교체된 토큰인지를 판별하는 값을 얻음

xt를 t 위치의 토큰이라고 하면, 판별자가 시그모이드 함수를 사용해 해당 토큰이 원래 토큰인지 아닌지 여부를 계산
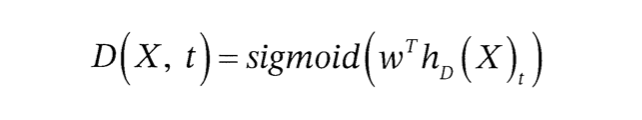
ELECTRA 모델
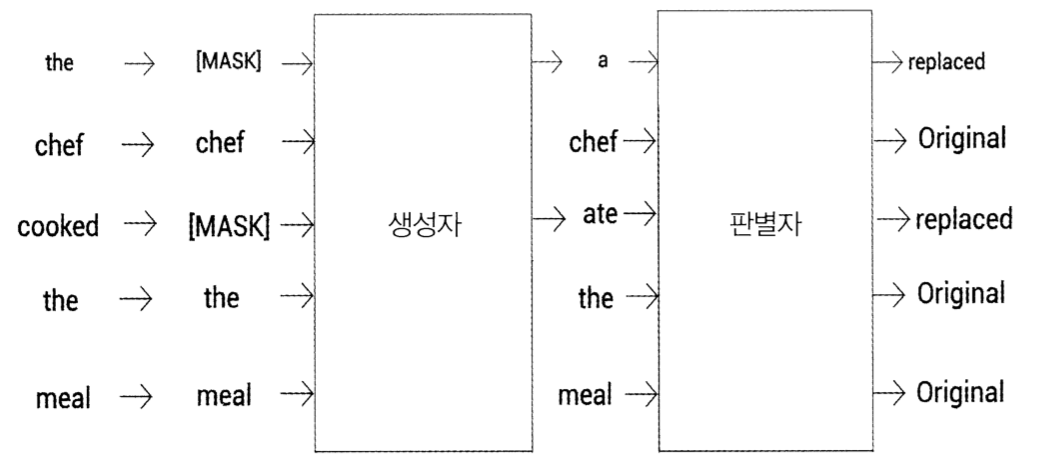
BERT와 비교했을 때 ELECTRA만 갖는 장점은 BERT는 MLM 태스크의 경우 전체 토큰의 15%만 마스킹한 후 학습을 진행하고 따라서 모델 학습은 15%의 마스크 된 토큰만 예측하는 것을 주목적으로 함
하지만 ELECTRA는 주어진 토큰의 원본 여부를 판별하는 방법으로 학습을 진행하기 때문에 모든 토큰을 대상으로 학습이 이루어짐
ELECTRA 모델 학습
생성자는 MLM 태스크를 사용해 학습
따라서 주어진 입력 X=[x1, x2, ... xn]에 대해 일부 위치를 선택해 마스킹
여기서 마스킹으로 선택한 위치를 M=[m1, m2, ... mn]이라고 한다면 선택한 위치의 토큰을 [MASK]로 변경
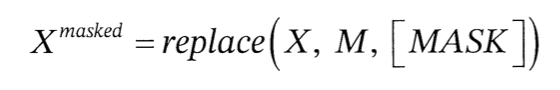
마스킹한 이후 토큰을 생성기에 입력하고 나서 마스크된 토큰에 대한 예측 결과를 얻음
이제 입력 토큰 X중 일부를 생성자에 의해 생성한 토큰으로 변경하는데 이유는 생성자에 의해 일부 토큰을 변경(손상)했기 때문
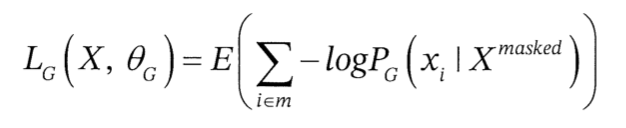
변경한 토큰 X를 판별자에 입력하면 판별자에서는 해당 토큰이 원래 토큰인지를 판단
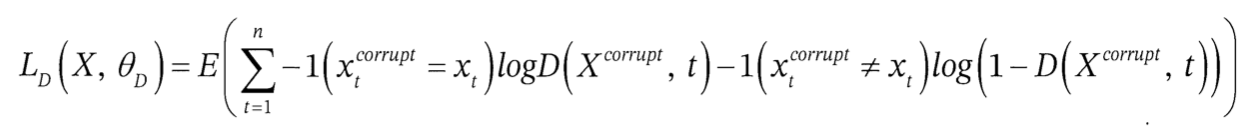
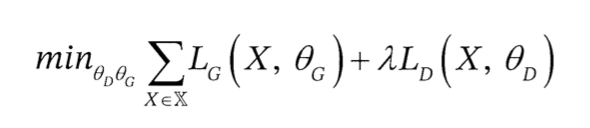
위 식에서 θ_G, θ_D는 각각 생성자와 판별자의 변수를 의미
효율적인 학습 방법 탐색
ELECTRA 모델을 효율적으로 학습시키기 위해 생성자와 판별자의 가중치 공유
즉, 생성자와 판별자 크기가 같다면 인코더의 가중치를 공유할 수 있음
하지만 생성자와 판별자 같은 크기로 하면 학습시간이 증가
따라서 생성자의 크기를 작게 해 모델 학습을 진행

링크 : https://github.com/google-research/electra
GitHub - google-research/electra: ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators - GitHub - google-research/electra: ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
github.com
transformers 라이브러리를 통해 ELECTRA 모델을 BERT 모델과 유사한 형태로 사용 가능
from transformers import ElectraTokenizer, ElectraModel
ELECTRA-small 판별자를 사용한다면 다음과 같이 사전 학습된 판별자를 다운로드 가능
model = ElectraModel.from_pretrained('google/electra-small-discriminator')
ELECTRA-small 생성자를 사용한다면 다음과 같이 모델을 다운
model = ElectraModel.from_pretrained('google/electra-small-generator')
SpanBERT로 스팬 예측
SpanBERT는 BERT의 파생 모델 중 하나이며 텍스트 범위를 예측하는 질문-응답과 같은 태스크에 주로 사용
'You are expected to know the laws of your country'
위 문장을 토큰화하면 다음과 같은 토큰을 얻음
tokens = [you, are, expected, to, know, the, laws, of, your, country]
SpanBERT에서는 토큰을 무작위로 마스킹하는 대신, 다음과 같이 토큰의 연속 범위를 무작위로 마스킹
tokens = [you, are, expected, to, know, [MASK], [MASK], [MASK], [MASK], country]
즉, 토큰의 위치를 무작위로 선정해 마스킹하는 것이 아닌, 토큰의 범위를 무작위로 마스킹
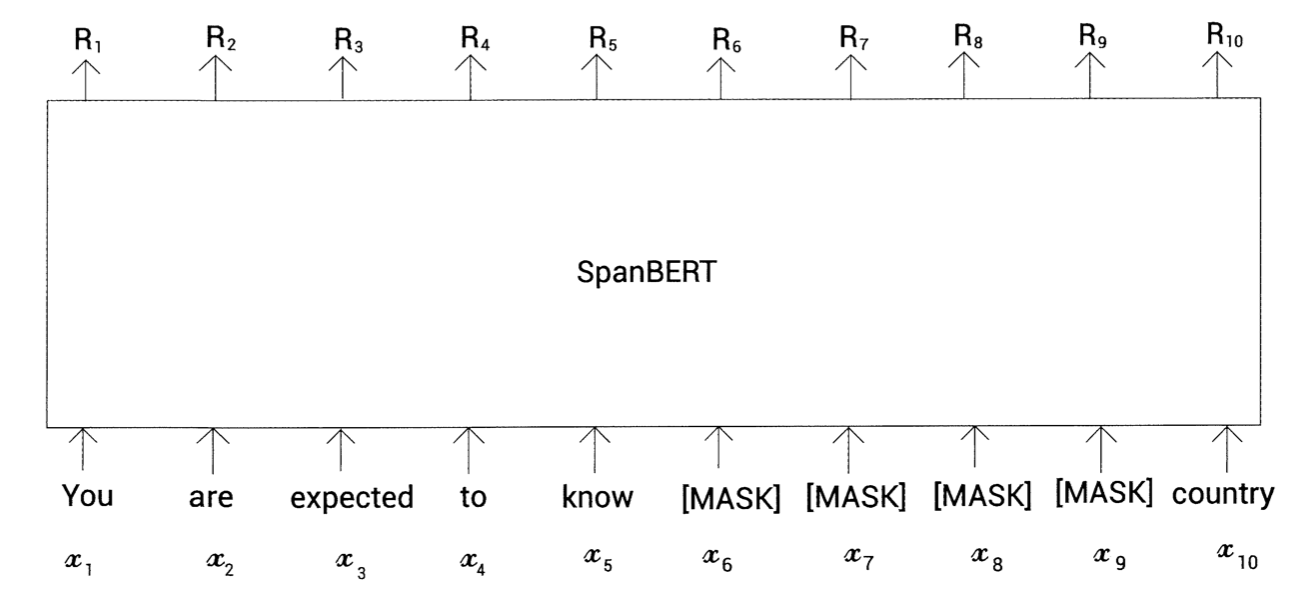
이 모델은 토큰 i에 대한 표현인 R을 출력
마스크 된 토큰을 예측하기 위해 MLM과 새로운 목적 함수인 SBO(span boundry objective)를 사용해 SpanBERT 학습
마스크된 토큰 x7을 예측한다고 하면 R7을 사용해서 마스크된 토큰을 예측
이때 R7을 분류기에 입력하면 사전에 있는 모든 단어에 대해 마스크된 토큰이 될 확률 얻을 수 있음
SBO에서는 마스크된 토큰을 예측하기 위해 해당하는 마스크된 토큰의 표현을 사용하는 대신 스팬 경계에 있는 토큰의 표현만 사용
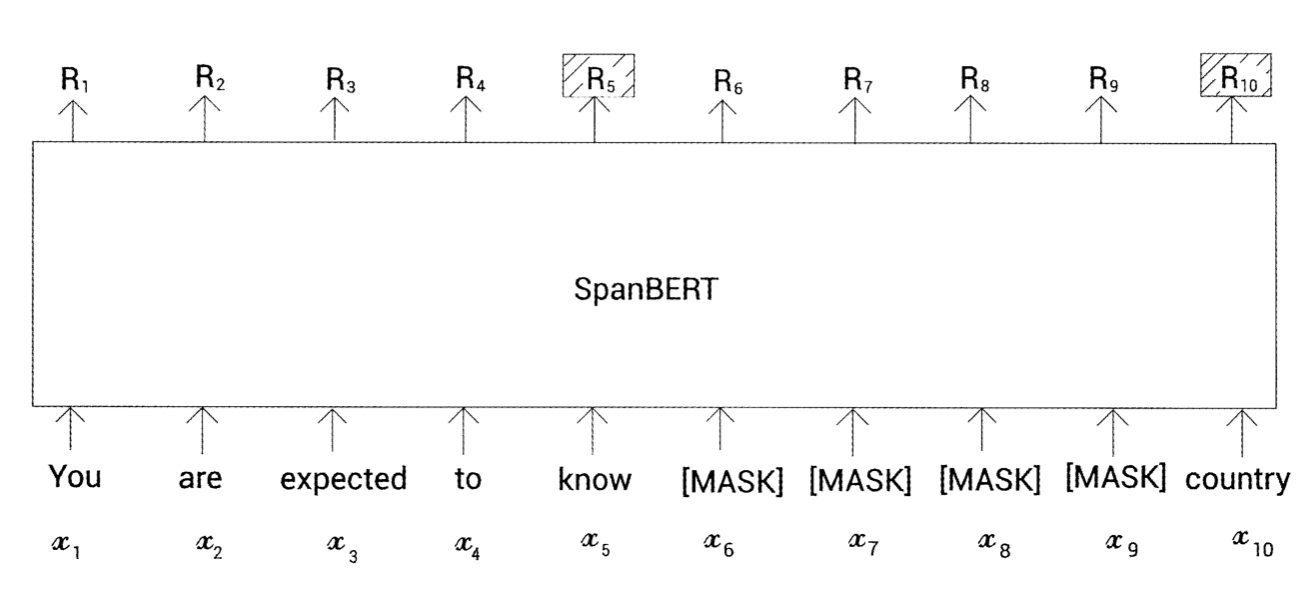
예를 들어 그림과 같이 x5와 x10이 스팬 경계의 토큰을 나타내고 R5, R10이 스팬 경계에 대한 표현이 됨
이제 마스크된 토큰을 예측하기 위해 모델에서는 두 가지 표현만 사용
예를 들어 마스크 된 토큰 x7을 예측하기 위해 모델은 스팬 경계의 토큰에 대한 표현인 R5와 R10만 사용
하지만 모델에서 마스크된 토큰을 예측하기 위해 범위의 경계에 있는 토큰의 표현만 사용하는데 이때 경계 안에 잇는 마스크된 토큰은 어떻게 구별할지가 문제가 됨
예를 들어 마스크된 토큰 x6과 x7모두 동일하게 R5, R10을 사용
이러한 이유로 스팬 경계의 토큰 표현과 별도로 모델은 마스크 된 토큰의 위치 임베딩값을 같이 사용
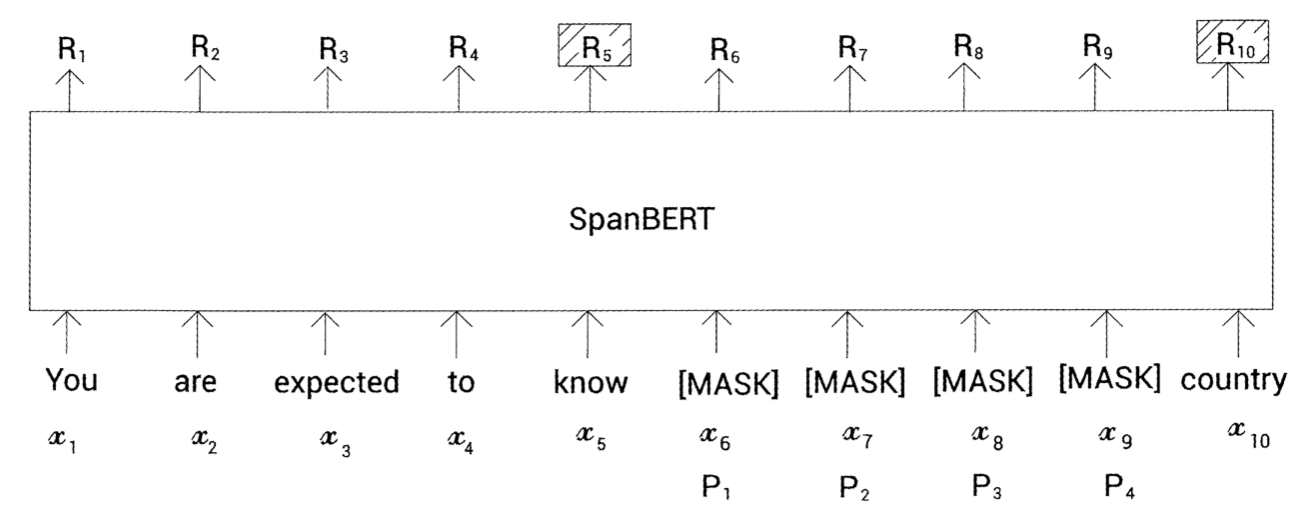
예를 들어 x7의 경우 마스크된 토큰을 기준으로 두 번째 위치에 있는 것을 알 수 있고 x7을 예측하기 위해 스팬 경계 토큰 표현인 R5, R10 그리고 마스크된 토큰의 위치 임베딩인 P2를 사용
SpanBERT는 MLM, SBO 2개의 목표를 설정
MLM은 마스크된 토큰을 예측하기 위해 해당 토큰의 표현만 사용하고 SBO의 경우는 마스크된 토큰을 예측하기 위해 스팬 경계 토큰의 표현과 마스크된 토큰의 임베딩 정보를 사용
SpanBERT 탐색
앞서 SpanBERT는 문장에서 연속적인 토큰 범위를 마스킹한다는 사실을 공부
x5와 xe를 각각 마스크된 토큰의 시작과 종료지점이라고 하면 위 토큰을 SpanBERT에 입력하고 모든 토큰에 대한 표현을 얻음
토큰 i에 대한 표현을 Ri라고 하면 스팬경계는 R_s-1과 R_e+1이 됨
먼저 SBO를 살펴보면 마스크 된 토큰 xi를 예측하기 위해 스팬 경계의 표현인 (R_s-1, R_e+1)과 마스크된 토큰의 위치 임베딩(P_i-s+1)의 3개 값을 사용
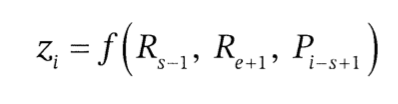
이때 f()는 기본적으로 2개의 피드포워드 네트워크와 GeLU 활성화 함수로 구성
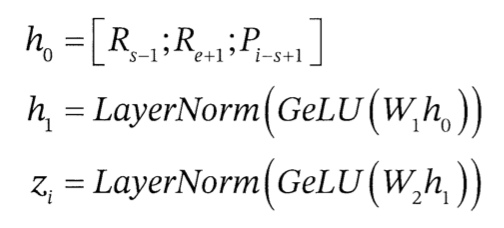
이제 마스크 된 토큰 xi를 예측하기 위해서는 zi 표현만 사용하면 됨
zi를 분류기에 입력하면 사전 안의 모든 단어가 마스크된 단어일 확률을 얻음
즉, SBO에서 마스크된 토큰 xi를 예측할 때는 스팬 경계 토큰의 표현과 마스크된 토큰의 위치 임베딩 정보를 가진 zi를 사용
MLM에서는 마스크된 토큰 xi를 예측하기 위해 해당 토큰의 표현인 Ri를 사용
분류기에서는 Ri를 입력해서 사전에 있는 모든 단어를 기준으로 마스크된 토큰이 될 확률을 얻음
SpanBERT의 손실 함수는 MLM과 SBO 로스를 더한 값이고 손실 값을 최소화하기 위해 SpanBERT를 학습
사전 학습된 SpanBERT를 질문-응답 태스크에 적용
transformers 라이브러리에서 제공하는 파이프라인 API를 사용
파이프라인은 transformers 라이브러리에서 제공하는 것으로 텍스트 분류부터 질문-응답에 이르는 복잡한 테스크를 좀 더 수월하게 수행하기 위해 제공하는 간단한 API
from transformers import pipeline먼저 pipeline을 호출
이제 질문-응답 태스크의 파이프라인을 설정
파이프라인 API에 수행하려는 태스크, 사전 학습된 모델 및 토크나이저 정보를 입력
spanbert-large-fine-tuned-squadv2 모델을 사용
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/spanbert-large-fine-tuned-squadv2",
tokenizer="SpanBERT/spanbert-large-cased"
)이제 qa_pipeline에 질문과 콘텍스트를 제공하면 응답을 포함한 결과를 얻을 수 있음
results = qa_pipeline({
'question': "What is machine learning?",
'context': "Machine learning is a subset of artificial intelligence. It is widely for creating a variety of applications such as email filtering and computer vision"
})결과를 출력해보면
print(results['answer'])
>>> a subset of artificial intelligencehttps://www.hanbit.co.kr/store/books/look.php?p_code=B2201215526
구글 BERT의 정석
이 책은 BERT의 기본 개념부터 다양한 변형 모델, 응용 사례까지 한 권으로 담은 실무 지침서다. 기계번역, 챗봇, 정보 검색 등 다양한 사례를 중심으로 BERT의 양방향을 활용하여 최소한의 데이터
www.hanbit.co.kr
'학회 세션 > 파인드 알파' 카테고리의 다른 글
| [Find-A] Markov process (0) | 2022.10.29 |
|---|---|
| [Find-A] 생성적 적대 신경망 (0) | 2022.10.02 |
| [Find-A][Pytorch] 정규화 (1) | 2022.09.25 |
| [Find-A][Pytorch] 학습률 (1) | 2022.09.25 |
| [Find-A][Pytorch] 초기화 (0) | 2022.09.25 |



