
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 시각화
- Python
- 데이터분석준전문가
- 태블로
- 회귀분석
- matplotlib
- 자격증
- scikit learn
- 이것이 코딩테스트다
- Google ML Bootcamp
- 데이터 분석
- 데이터분석
- 통계
- 이코테
- r
- 데이터 전처리
- SQL
- ADsP
- Deep Learning Specialization
- pandas
- pytorch
- SQLD
- 파이썬
- tableau
- sklearn
- 머신러닝
- 코딩테스트
- ML
- IRIS
- 딥러닝
- Today
- Total
목록시각화 (7)
함께하는 데이터 분석
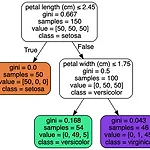 [Find-A][Scikit Learn] Decision Tree
[Find-A][Scikit Learn] Decision Tree
의사결정 나무(Decision Tree) 분류와 회귀 작업, 다중출력 작업도 가능한 다재다능한 머신러닝 알고리즘 최근에 자주 사용되는 강력한 머신러닝 알고리즘 중 하나인 랜덤 포레스트의 기본 구성 요소 1. 의사결정 나무 학습과 시각화 from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier iris = load_iris() X = iris['data'][:, (2, 3)] y = iris['target'] 사이킷런의 iris 데이터를 불러오고 X에 PetalLength, PetalWidth y에 꽃의 품종인 Setona, Versicolor, Virginica를 할당 tree_clf = DecisionTr..
 [Python] 시각화 / graphviz
[Python] 시각화 / graphviz
파이썬에서 의사결정 나무를 시각화할 때 graphviz 라이브러리를 import 해야 합니다. 이 라이브러리는 추가로 설치해야 하는데 윈도우를 사용하는 사람들의 설치법은 구글링을 하면 많지만 맥을 사용하는 사람은 그 방법으로 했을 때 오류가 많고 안 되는 경우가 많습니다. 그래서 제가 오랫동안 여러 가지 방법을 시도해보고 성공한 아나콘다에서의 설치방법을 알려드리겠습니다. 1. Homebrew https://brew.sh/index_ko Homebrew The Missing Package Manager for macOS (or Linux). brew.sh Homebrew는 mac os에서 라이브러리 설치를 도와줍니다. Spotlight에서 터미널을 검색하여 실행한 후 /bin/bash -c "$(curl ..
 [Python] Matplotlib 그래프에 텍스트 삽입
[Python] Matplotlib 그래프에 텍스트 삽입
안녕하세요! 오늘은 지금까지 그렸던 한 개의 선 그래프나 여러 개의 선 그래프에 텍스트를 삽입하는 것을 알아보겠습니다. 그래프는 전 포스트에 작성한 코드를 그대로 가져올 것입니다. 각각의 그래프에 y값을 보기 쉽게 넣어주도록 할게요. 한 개의 선 그래프에 텍스트 삽입 import numpy as np import pandas as pd import matplotlib.pyplot as plt import random import matplotlib.pyplot as plt plt.rc('font', family = 'AppleGothic') # mac # plt.rc('font', family = 'Malgun Gothic') # window plt.rc('font', size = 12) plt.rc('..
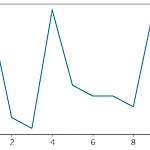 [Python] Matplotlib 선 그래프와 배경 꾸미기
[Python] Matplotlib 선 그래프와 배경 꾸미기
이번에는 선 그래프를 그렸던 것을 바탕으로 선 그래프의 모양이나 배경을 꾸미는 것을 알아보겠습니다. 라이브러리 불러오기 import matplotlib.pyplot as plt import random x, y 리스트 설정 x = [i for i in range(1, 11)] random.seed(42) y=[] for i in range(1,11): z=random.randint(10,21) y.append(z) print(y) >>> [20, 11, 10, 21, 14, 13, 13, 12, 21, 11] 선 굵기 설정 plt.plot(x, y) plt.show() 이것이 기본으로 나오는 선의 굵기입니다. 선의 굵기를 조금 키워보겠습니다. plt.plot(x, y, linewidth = 12) # p..
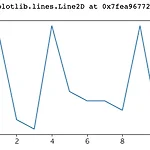 [Python] Matplotlib 기본 설정 & 선 그래프
[Python] Matplotlib 기본 설정 & 선 그래프
오늘은 Python에서 Matplotlib을 활용하여 데이터를 시각화하는 방법을 공부하겠습니다. 그럼 시작해볼게요. 라이브러리 불러오기 import matplotlib.pyplot as plt import random 위의 matplotlib이 우리가 공부해 볼 라이브러리이고 밑의 random은 왜 썼는지 밑에서 보여드릴게요. x, y 리스트 설정 x = [i for i in range(1, 11)] random.seed(42) y=[] for i in range(1,11): z=random.randint(10,21) y.append(z) print(y) >>> [20, 11, 10, 21, 14, 13, 13, 12, 21, 11] x에 1부터 10까지 리스트를 생성했고 y에 11부터 20까지 숫자 중..
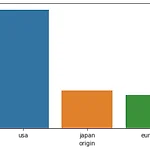 [Python] Seaborn을 활용한 범주형 변수의 시각화
[Python] Seaborn을 활용한 범주형 변수의 시각화
안녕하세요! 이번에는 Python에서 Seaborn을 활용하여 범주형 변수의 시각화를 공부해보겠습니다. 라이브러리 실행 import numpy as np import pandas as pd import seaborn as sns 데이터 불러오기 mpg = sns.load_dataset('mpg') 1개의 범주형 변수에 대한 시각화 sns.countplot(data = mpg, x='origin') countplot은 x나 y에 하나의 범주형 변수만 넣으면 나머지는 개수로 표현됩니다. sns.countplot(data = mpg, y='origin') mpg['origin'].value_counts() >>> usa 249 japan 79 europe 70 Name: origin, dtype: int64 ..
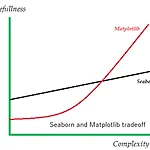 [Python] Seaborn을 활용한 수치형 변수의 시각화
[Python] Seaborn을 활용한 수치형 변수의 시각화
안녕하세요! 오늘은 Python에서 Seaborn을 이용하여 수치형 변수의 시각화를 공부해보겠습니다. Seaborn은 Matplotlib보다 고수준으로 코드도 간단하고 미학적으로도 괜찮습니다. 그렇다면 Matplotlib보다 Seaborn이 좋다는 것일까요? 결론적으로는 두 가지 라이브러리를 다 사용할 줄 알아야 합니다. Matplotlib과 Seaborn을 같이 사용했을 때 Seaborn만을 사용했을 때 보다 더 좋은 결과물을 얻어낼 수 있습니다. 이처럼 결국에는 두 가지 라이브러리를 함께 사용하는 것이 효과적입니다. 그러면 오늘은 Seaborn을 이용하여 시각화를 시작해볼까요? 라이브러리 실행 import numpy as np import pandas as pd import seaborn as sns..