
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- SQL
- scikit learn
- 태블로
- 회귀분석
- Python
- IRIS
- 통계
- 자격증
- sklearn
- 이것이 코딩테스트다
- matplotlib
- 파이썬
- tableau
- ADsP
- 머신러닝
- 데이터 분석
- 데이터분석준전문가
- 이코테
- 코딩테스트
- SQLD
- Google ML Bootcamp
- pandas
- Deep Learning Specialization
- r
- 시각화
- 딥러닝
- 데이터분석
- ML
- pytorch
- 데이터 전처리
Archives
- Today
- Total
함께하는 데이터 분석
[ML] XGBoost 본문
XGBoost
XGBoost는 "eXtreme Gradient Boosting"에서 따온 이름입니다
XGBoost는 Gradient Boosting 방법 중 하나로 많은 장점이 존재합니다
장점
- 효율성, 유연성이 뛰어남
- overfitting 방지 가능(과적합 규제)
- 신경망 모델에 비해 시각화와 직관적인 이해가 쉬움
- cross validation을 지원
- 높은 성능을 나타내어 kaggle, dacon에 많이 사용
- early stopping(조기종료) 기능이 있음
- missing value를 내부적으로 처리
단점
- 하이퍼파라미터 수가 너무 많음
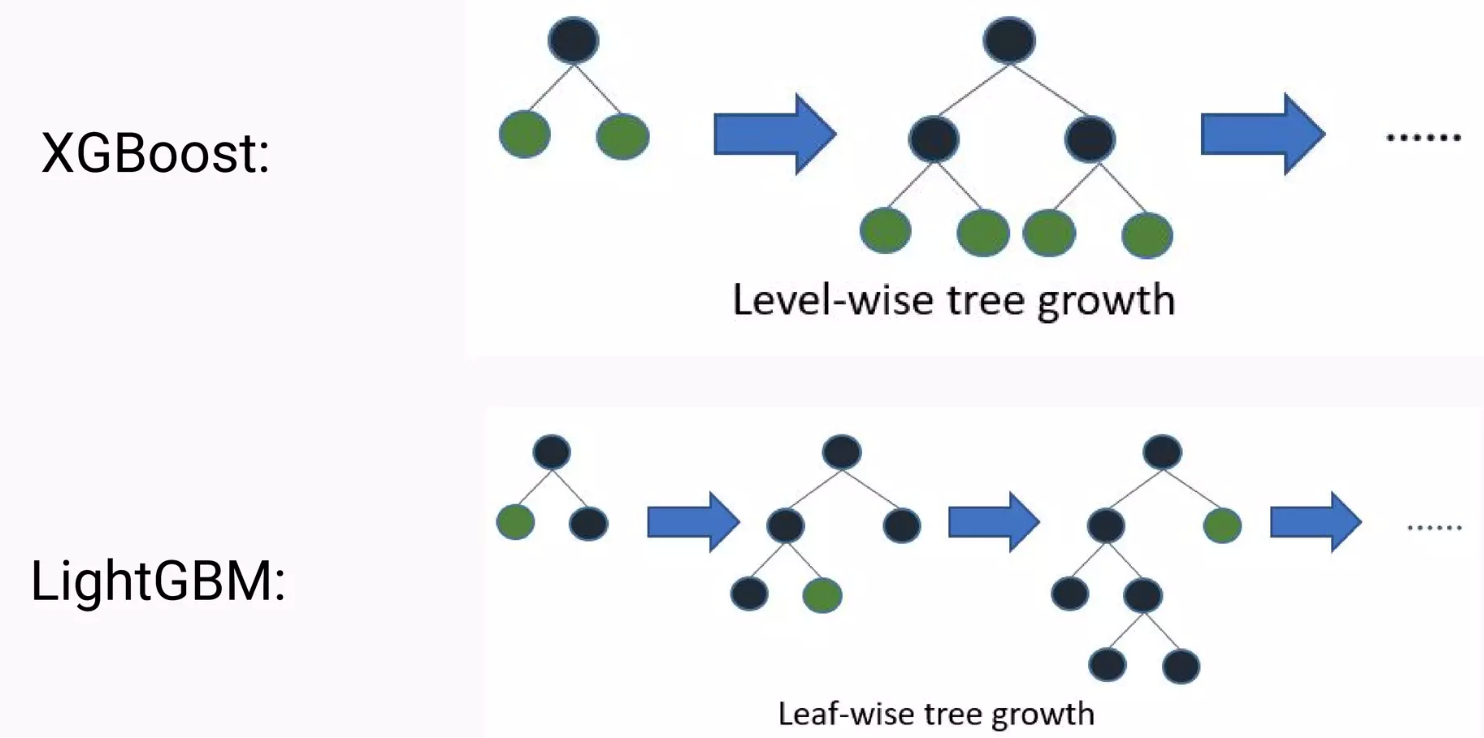
XGBoost는 앞선 LightGBM 포스팅에서 본 것과 같이 level-wise로 수평적으로 확장됩니다
Python 실습
import numpy as np
import warnings
warnings.filterwarnings('ignore')from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris['data'], (iris['target'] == 2).astype(np.float64)from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=124)from xgboost import XGBClassifier
model = XGBClassifier(random_state=42)
model.fit(X_train, y_train)
pred = model.predict(X_test)from sklearn.metrics import accuracy_score
print('XGBoost Accuracy : ', round(accuracy_score(y_test, pred) * 100, 2))
>>> XGBoost Accuracy : 90.0'데이터분석 공부 > ML | DL' 카테고리의 다른 글
| [ML] 여러모델 평가지표 (1) | 2024.03.17 |
|---|---|
| [ML] CatBoost (0) | 2023.01.23 |
| [ML] LightGBM (0) | 2023.01.20 |
| [ML] 분류 모델 성능 평가 지표 (0) | 2023.01.17 |
| [ML] Gradient Boosting Machine (0) | 2023.01.15 |
'데이터분석 공부/ML | DL' Related Articles
more


