
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 데이터분석준전문가
- 데이터 전처리
- 데이터 분석
- 회귀분석
- IRIS
- 시각화
- matplotlib
- r
- 이것이 코딩테스트다
- 코딩테스트
- ADsP
- pytorch
- scikit learn
- SQL
- 딥러닝
- sklearn
- tableau
- 데이터분석
- pandas
- Google ML Bootcamp
- 머신러닝
- 파이썬
- SQLD
- 태블로
- 자격증
- ML
- Deep Learning Specialization
- Python
- 이코테
- 통계
- Today
- Total
함께하는 데이터 분석
[NLP] Transformer① 본문
Transformer
- 2017 NIPS에서 Google이 소개
- CNN이나 RNN이 주를 이루었던 연구들에서 벗어난 아예 새로운 모델이고 실제 적용했을 때 큰 성능 향상을 보임
- multi-head self-attention을 이용해 sequential computation을 줄여 더 많은 부분을 병렬처리가 가능하며 더 많은 단어들 간의 dependency를 모델링 함

이를 하나의 black box라고 보면 어떤 한 언어로 된 하나의 문장을 입력으로 받아 다른 언어로 된 번역을 출력으로 내놓음

black box를 열어보면 우리는 인코딩 부분, 디코딩 부분 그리고 그 사이를 이어주는 connection들을 보게 됨
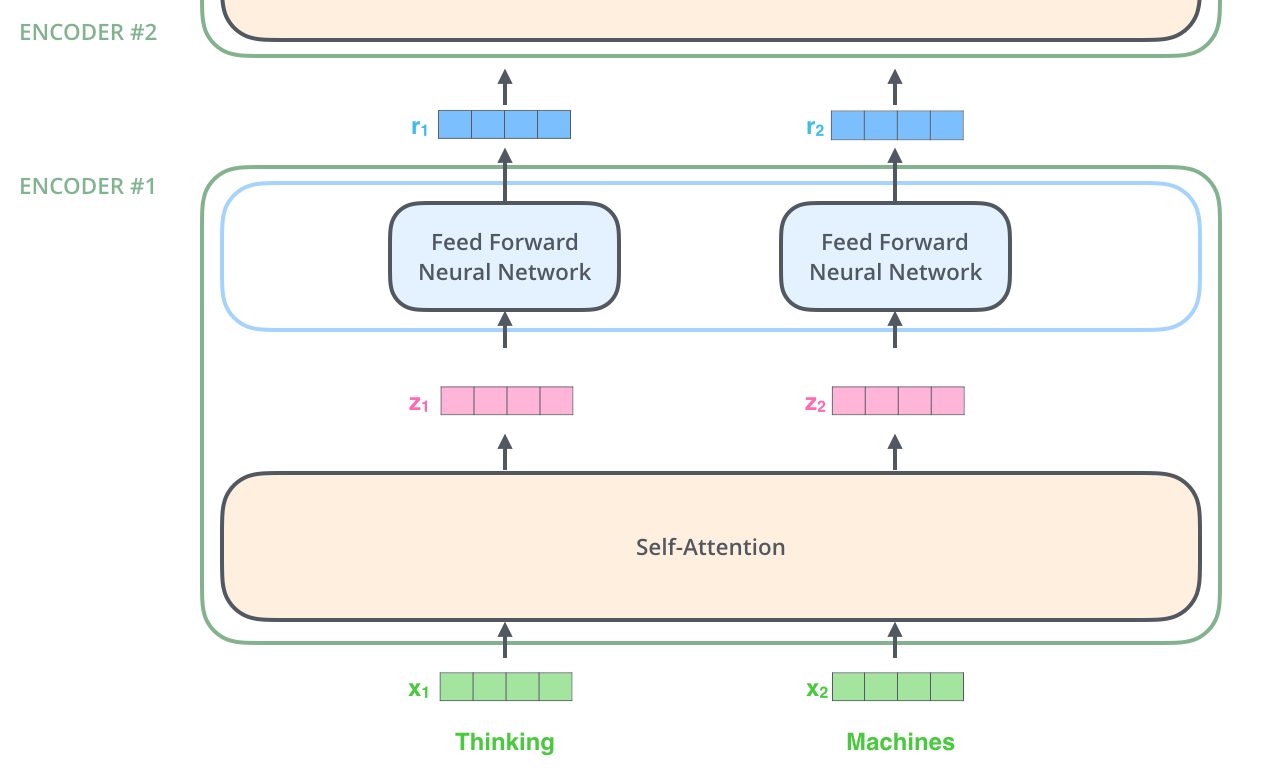
인코딩 부분은 여러 개의 인코더를 쌓아 올려 만든 것이고 디코딩 부분은 인코딩 부분과 동일한 개수만큼의 디코더를 쌓은 것

인코더들은 모두 정확히 똑같은 구조를 갖고 있지만, 그들 간에 같은 weight를 공유하진 않음

하나의 인코더를 보면 위와 같이 두 개의 sub-layer로 구성되어 있는데 일단 인코더에 들어온 입력은 self-atttention layer를 지나가게 됨
그리고 입력이 self-attention 층을 통과하여 나온 출력은 다시 feed-forward 신경망으로 들어감

디코더 또한 encoder에 있는 두 layer층 모두를 가지고 있고 추가로 두 층 사이에 encoder-decoder attention이 포함되어 있음
이는 디코더가 입력 문장 중에서 각 타임 스텝에서 가장 관련 있는 부분에 집중할 수 있도록 해줌
벡터/텐서들을 기준으로 모델 살펴보기
대부분의 NLP 관련 모델과 마찬가지로 먼저 입력 단어들을 임베딩 알고리즘을 이용해 벡터로 바꿔야 함

각 단어들은 512 크기의 벡터 하나로 임베딩 됨
모든 인코더들은 크기 512의 벡터의 리스트를 입력으로 받음
이 벡터는 가장 밑단의 인코더의 경우에는 word 임베딩이 될 것이고, 다른 인코더들에서는 바로 전의 인코더의 출력일 것
입력 문장의 단어들을 임베딩 한 후, 각 단어에 해당하는 벡터들은 인코더 내의 두 개의 sub-layer로 들어가게 됨

각 위치에 있는 각 단어가 그만의 path를 통해 인코더에서 흘러간다는 Transformer 모델의 주요 성질을 볼 수 있음
self-attention층에서 이 위치에 따른 path들 사이에 다 dependency가 있음
반면 feed-forward층은 이런 dependency가 없기에 feed-forward layer내의 이 다양한 path들은 병렬처리될 수 있음
Encoding
앞서 설명한 것과 같이, 인코더는 입력으로 벡터들의 리스트를 받음
이 리스트를 먼저 self-attention layer에, 그다음으로 feed-forward 신경망에 통과시키고 결과물을 다음 인코더에 전달
각 위치의 단어들은 각각 다른 self-encoding 과정을 거침
그다음으로 모두에게 같은 과정인 feed-forward 신경망을 거침
Self-Attention
"The animal didn't cross the street because it was too tired"
이 문장에서 "it"이 가리키는 것은 사람에게는 당연히 animal을 말한다고 생각하지만 신경망 모델은 그렇게 간단하지 않음
모델이 "it"이라는 단어를 처리할 때, 모델은 self-attention을 이용하여 "it"과 "animal"을 연결할 수 있음
모델이 입력 문장 내의 각 단어를 처리해 나감에 따라, self-attention은 입력 문장 내 다른 위치에 있는 단어들을 보고 거기서 힌트를 받아 현재 타깃 위치의 단어를 더 잘 임베딩할 수 있음
즉, self-attention은 현재 처리 중인 단어에 다른 연관이 있는 단어들의 맥락을 넣어주는 것

가장 윗단에 있는 인코더에서 "it"이라는 단어를 임베딩할 때, attention 메커니즘은 입력의 여러 단어들 중 "The animal"이라는 단어에 집중하고 이 단어의 의미 중 일부를 "it"이라는 단어를 임베딩할 때 이용
Self-Attention 계산
여러 가지 벡터들을 통해 어떻게 self-attention을 계산할 수 있는지 확인한 후 행렬을 이용해서 실제 어떻게 구현돼 있는지 확인할 것
self-attention 계산의 가장 첫 단계는 인코더에 입력된 벡터들(각 단어의 임베딩 벡터)에서 부터 각 3개의 벡터들 만들어내는 일
우리는 각 단어에 대해 Query, Key, Value 벡터를 생성하고, 이 벡터들은 입력 벡터에 대해 3개의 학습 가능한 행렬들을 각각 곱함으로써 만들어짐

x1을 weight 행렬인 WQ로 곱하는 것은 현재 단어와 관련된 query 벡터인 q1을 생성
같은 방법으로 입력 문장에 있는 각 단어에 대한 Query, Key, Value 벡터를 만들 수 있음
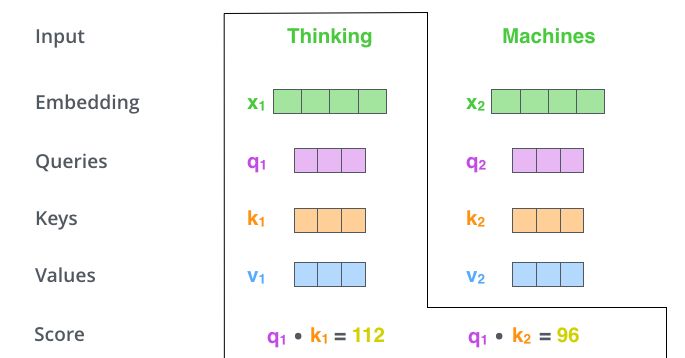
두 번째 스텝은 점수를 계산하는 것인데, 입력 문장 속 특정 단어와 다른 모든 단어들에 대해 각각의 점수를 계산해야 함
이 점수는 현재 위치의 이 단어를 인코드 할 때 다른 단어들에 대해 얼마나 집중을 해야 할지를 결정
점수는 현재 단어의 query 벡터와 점수를 매기려 하는 다른 위치에 있는 단어의 key 벡터의 내적으로 계산
두 번째 점수는 q1과 k2의 내적일 것
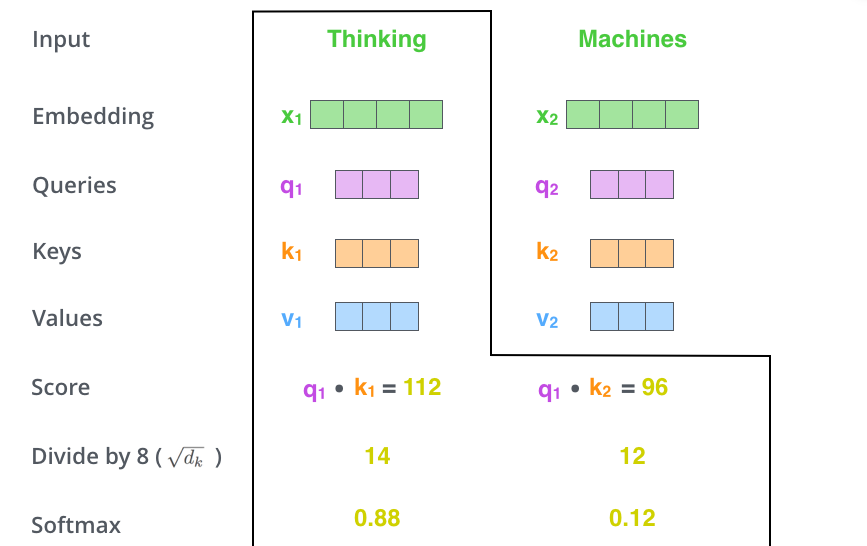
세 번째와 네 번째 단계는 이 점수들을 key 벡터의 사이즈인 64의 제곱근인 8로 나누는 것이고
이를 통해 더 안정적인 gradient를 갖게 되고, 이 값을 softmax 계산을 통과시켜 모든 점수들을 양수로 만들고 합을 1로 만들어줌
이 softmax 점수는 현재 위치의 단어의 인코딩에 있어 얼마나 각 단어들의 표현이 들어갈 것인지를 결정
당연하게 현재 위치의 단어가 가장 높은 점수를 가지며 가장 많은 부분을 차지
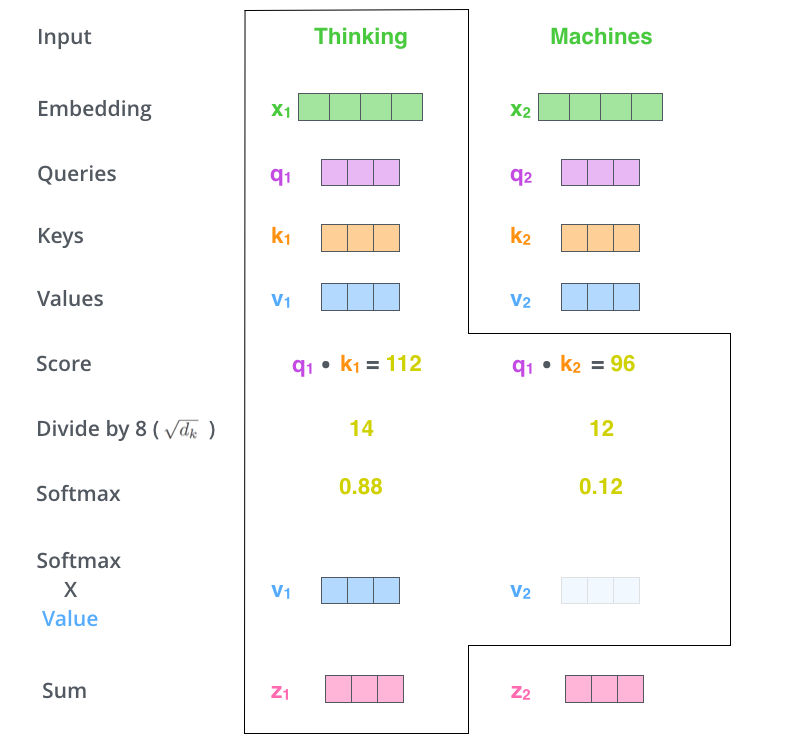
다섯 번째 단계는 이제 입력의 각 단어들의 value 벡터에 이 점수를 곱하는 것
이것을 하는 이유는 우리가 집중하고 싶은 관련 있는 단어들은 남겨두고, 관련 없는 단어들은 0.001과 같은 작은 숫자를 곱해 없애버리기 위함
마지막 여섯 번째 단계는 이 점수로 곱해진 weighted value 벡터들을 다 합해버리는 것
이 단계의 출력이 현재 위치에 대한 self-attention layer의 출력이 됨
이 여섯 가지 과정이 self-attention 계산과정이고, 우리는 이 결과로 나온 벡터를 feed-forward 신경망으로 보내게 됨
그러나 실제 구현에서는 빠른 속도를 위해 이 모든 과정들을 벡터가 아닌 행렬의 형태로 진행
Self-Attention 행렬 계산
가장 첫 스텝은 입력 문장에 대해 Query, Key, Value 행렬들을 계산하는 것

이를 위해 우리는 입력 벡터들(임베딩 벡터들)을 하나의 행렬 X로 쌓아 올리고 그것을 우리가 학습할 weight 행렬들인 WQ, WK, WV로 곱함
마지막으로 현재 행렬을 이용하고 있으므로 앞서 설명했던 self-attention 계산 2~6단계 까지를 하나의 식으로 압축할 수 있음
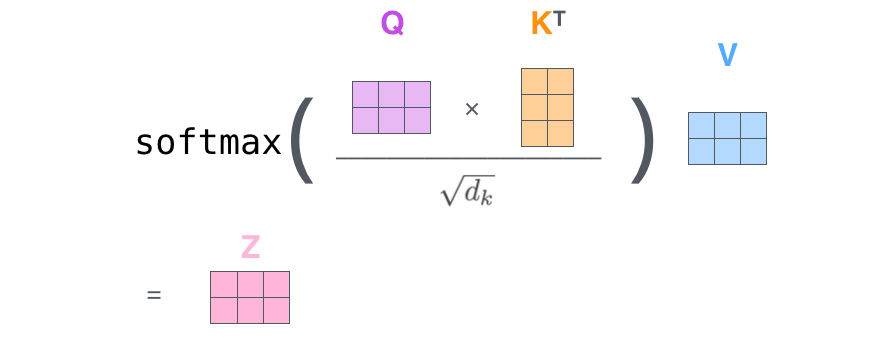
Multi-headed
위의 self-attention layer에다 "multi-headed" attention이라는 메커니즘을 더해 개선
이 메커니즘은 아래 두 가지 방법으로 attention layer의 성능을 향상시킴
- 모델이 다른 위치에 집중하는 능력을 확장시킴. 위의 예시에서는 z1이 모든 다른 단어들의 인코딩을 조금씩 포함했지만, 사실 이 것은 실제 자기 자신에게만 높은 점수를 줘 자신만을 포함해도 됐을 것. 이것은 "The animal didn't cross the street because it was too tired"와 같은 문장을 번역할 때 "it"이 무엇을 가리키는지에 대해 알아낼 때 유용함
- attention layer가 여러 개의 "representation 공간"을 가지게 해 줌. 계속해서 보겠지만, multi-headed attention을 이용함으로써 우리는 여러 개의 query/key/value weight 행렬들을 가지게 됨. 이 각각의 query/key/value set은 랜덤으로 초기화되어 학습됨. 학습이 된 후 각각의 세트는 입력 벡터들에 곱해져 벡터들을 각 목적에 맞게 투영시키게 됨. 이러한 세트가 여러 개 있다는 것은 각 벡터들은 각각 다른 representation 공간으로 나타낸다는 것을 의미
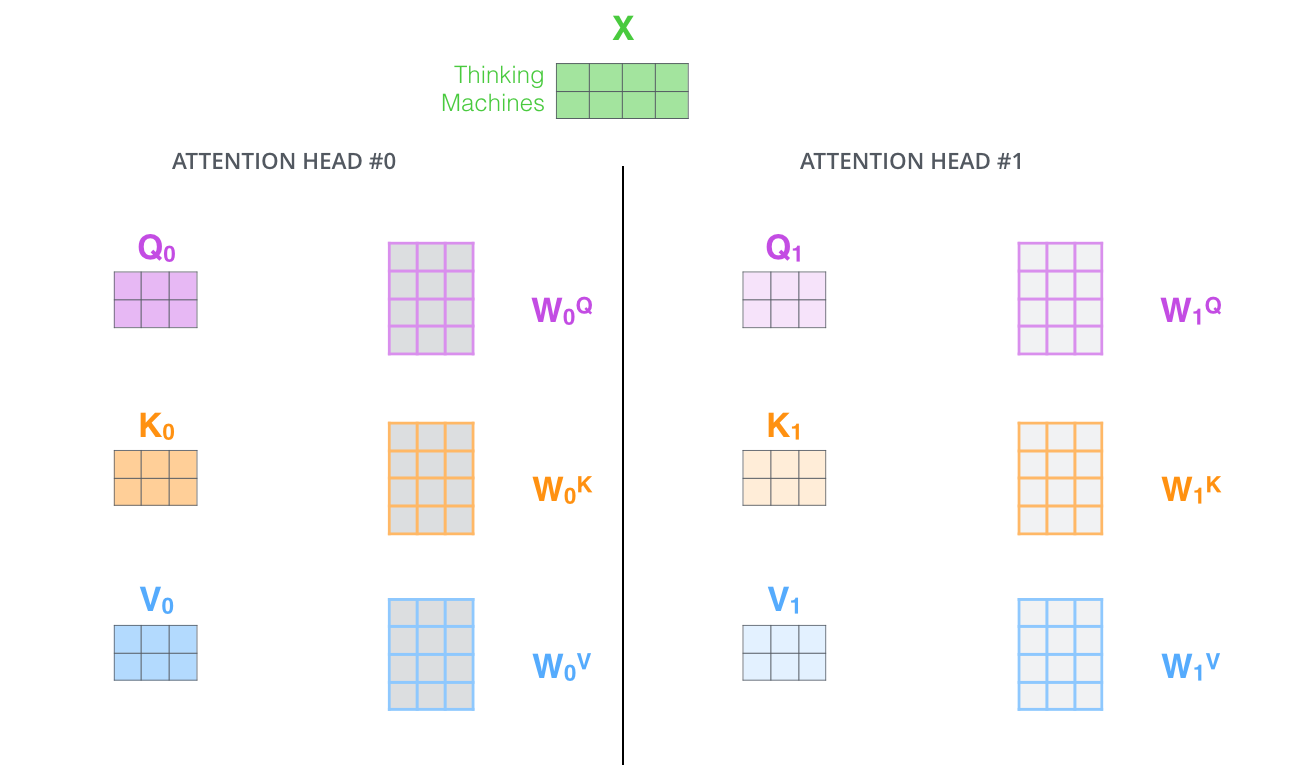
multi-headed attention을 이용하기 위해 우리는 각 head를 위해서 각각의 다른 query/key/value weight 행렬들을 모델에 가지게 됨
이전에 설명한 것과 같이 우리는 입력 벡터들의 모음인 행렬 X를 WQ/WK/WV 행렬들로 곱해 각 head에 대한 Q/K/V 행렬들을 생성
같은 self-attention 계산 과정을 8개의 다른 weight 행렬들에 대해 8번 거치게 되면, 8개의 서로 다른 Z행렬을 가지게 됨

그러나 문제는 이 8개의 행렬을 바로 feed-forward layer으로 보낼 수 없다는 것
feed-forward layer은 한 위치레 대해 오직 한 개의 행렬만을 input으로 받을 수 있음
그러므로 이 8개의 행렬을 하나의 행렬로 합치는 방법을 고안해내야 함

방법은 아주 간단하게 모두 이어 붙여 하나의 행렬로 만들어버리고, 그다음 하나의 또 다른 weight행렬인 W0를 곱함
여러 개의 행렬들이 등장하긴 했지만 사실상 multi-headed self-attention은 이게 다임
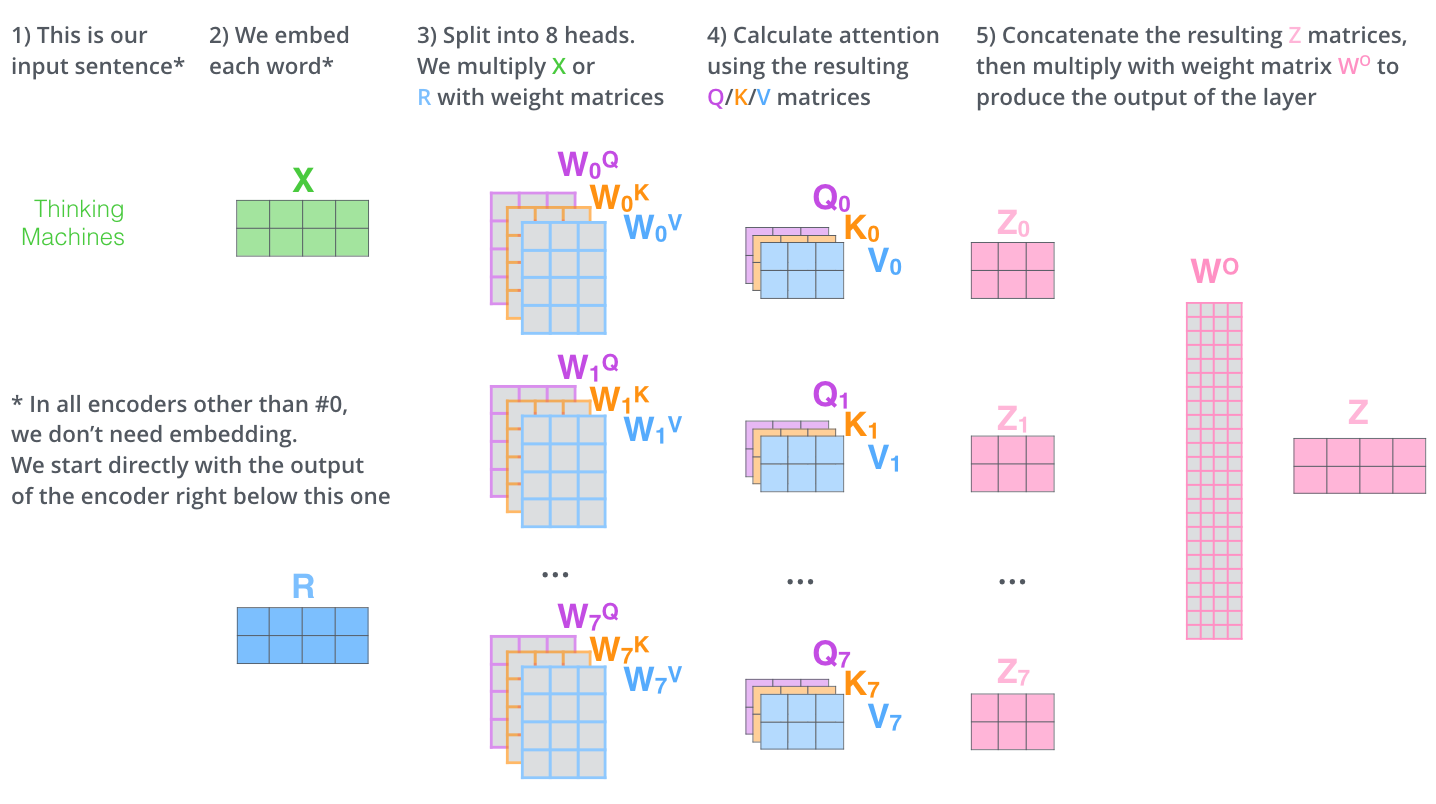
이 모든 것을 하나로 표현해서 정리한 그림
마지막으로 예제 문장을 multi-head attention과 함께 볼 것
그중에서도 특히 "it"이란 단어들 인코드 할 때 여러 개의 attention이 각각 어디에 집중하는지를 볼 것

우리가 "it"이란 단어를 인코드 할 때, 주황색의 attention head는 "The animal"에 가장 집중하고 있음
반면에 초록색의 attention head는 "tire"이라는 단어에 집중을 하고 있음
모델은 이 두 개의 attention head를 이용하여 "animal"과 "tire" 두 단어 모두에 대한 representation을 "it"의 representation에 포함시킬 수 있음

그러나 이 모든 attention head들을 하나의 그림으로 표현하면, attention의 의미를 해석하기가 어려워짐
The Illustrated Transformer – NLP in Korean – Anything about NLP in Korean
The Illustrated Transformer
저번 글에서 다뤘던 attention seq2seq 모델에 이어, attention 을 활용한 또 다른 모델인 Transformer 모델에 대해 얘기해보려 합니다. 2017 NIPS에서 Google이 소개했던 Transformer는 NLP 학계에서 정말 큰 주목을
nlpinkorean.github.io
'데이터분석 공부 > NLP' 카테고리의 다른 글
| [NLP] Transformer② (0) | 2023.02.05 |
|---|
