Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- matplotlib
- pandas
- ML
- 파이썬
- 머신러닝
- scikit learn
- 이코테
- 통계
- 이것이 코딩테스트다
- sklearn
- 데이터분석준전문가
- 데이터분석
- 시각화
- SQLD
- pytorch
- ADsP
- Python
- 코딩테스트
- SQL
- 딥러닝
- r
- IRIS
- 자격증
- Deep Learning Specialization
- 회귀분석
- tableau
- 데이터 전처리
- 태블로
- 데이터 분석
- Google ML Bootcamp
Archives
- Today
- Total
함께하는 데이터 분석
[데이터 마이닝] 의사결정나무(Decision Trees) 본문
오늘은 데이터 마이닝의 분석방법 중 하나인
의사결정나무를 알아보겠습니다.
의사결정나무의 정의
- 과거에 수집된 데이터들을 분석하여 이들 사이에 존재하는 패턴 즉, 범주별 특성을 속성의 조합으로 나타내는 분류 모형
의사결정나무의 목적
- 새로운 데이터에 대해 분류(Classification)하거나 해당 범주의 값을 예측하는 것
변수 유형에 따른 분류
- 범주형 : 분류나무(Classification Tree)
- 연속형 : 회귀나무(Regression Tree)
의사결정나무 구성요소
- 노드(Node)
- 가지(Branch)
- 깊이(Depth) : 깊어질수록 복잡도 상승

제일 위의 신용도에서 가지가 쳐서 나오므로 root node라고 하고
마지막 노드를 terminal node라고 합니다.
여기서 신용도와 나이, 성별을 부모노드와 자식노드라고도 부릅니다.
모수적 비모수적 방법에 따른 여러 가지 알고리즘
- 모수적인 방법(카이제곱 검정에 근거)
- AID
- THAID
- CHAID
- 비모수적인 방법
- ID3(Iterative Dichotomiser 3) - 다지분류
- CART(Classification And Regression Tree) - 이진분류
- C4.5(successor of ID3) - 다지분류
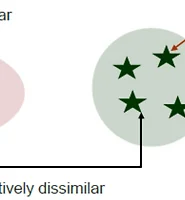
불순도 측도
- 분리변수(Splitting Variable)와 기준값(Threshold)을 정하기 위한 불순도 측도를 통해 결정해야 함
- 순도가 증가하고 불확실성이 감소하는 것을 정보이론에서 정보획득(information gain)이라 함
- 지니지수 : 값이 클수록 이질적이며 순수도(purity)가 낮다

- 엔트로피지수
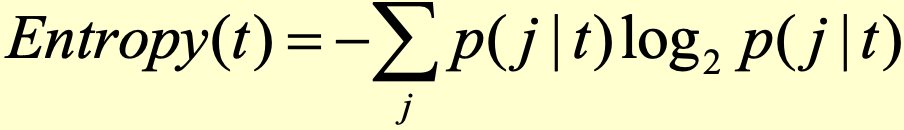
- 분류오류

| Discrete target variable | Continuous target variable | |
| CHAID(다지분류) | Chi-Square statistics | ANOVA F-statistics |
| CART(이진분류) | Gini index | Variance reduction |
| C4.5 | Entrophy index |
비율과 불순도 그래프

예를 들어 o와 x의 비율이 1/2라고 하고 o o o x x x 가 있다고 하면
지니지수 값을 계산해 봤을 때 1-(1/2)^2-(1/2)^2으로 0.5가 되는 것을 알 수 있습니다.
만약 o x x x x x라고 하면 1-(1/6)^2-(5/6)^2으로 0.277로 작아지므로
순수도가 높고 불순도가 낮다고 할 수 있습니다.
가지치기(pruning)
- 검증 데이터에 대한 오분류율이 증가하는 시점에서 적절한 가지치기를 수행(가지를 제거)
- 나무가 너무 커지면 과적합(overfitting)할 가능성이 커짐(가지치기를 수행해야 함)
의사결정나무의 장점
- 모형의 해석과 이해가 쉬움
- 이상치(outlier)에 덜 민감
- 결측치를 미리 제거해줄 필요 없음
의사결정나무의 단점
- 데이터의 변화에 민감. 초기 분할이 결과에 영황을 크게 줌
- 좋은 모형을 만들기 위해 많은 데이터가 필요
- 학습시간이 오래 걸림
- 항상 직각으로 분류
'통계학과 수업 기록 > 데이터 마이닝' 카테고리의 다른 글
| [데이터 마이닝] 연관성 분석(Association Analysis) (0) | 2022.04.06 |
|---|---|
| [데이터 마이닝] Cluster Analysis (0) | 2022.04.01 |
| [데이터 마이닝] 로지스틱 단순회귀모형 (0) | 2022.03.24 |
| [데이터 마이닝] 분석기법 분류 (0) | 2022.03.15 |
| [데이터 마이닝] 데이터분석과 방법론 개요 (0) | 2022.03.14 |
'통계학과 수업 기록/데이터 마이닝' Related Articles
more