
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- ML
- 파이썬
- 자격증
- 태블로
- 통계
- 딥러닝
- scikit learn
- 데이터 전처리
- 시각화
- ADsP
- 데이터분석
- r
- 이코테
- 데이터분석준전문가
- IRIS
- 머신러닝
- SQLD
- matplotlib
- 데이터 분석
- 회귀분석
- Python
- Google ML Bootcamp
- SQL
- Deep Learning Specialization
- 이것이 코딩테스트다
- 코딩테스트
- pandas
- sklearn
- pytorch
- tableau
- Today
- Total
함께하는 데이터 분석
[SQL] 데이터 조회 - SELECT 본문
오늘은 데이터를 조회하는 데 사용하는
Select를 조금 더 자세히 알아보겠습니다.
Select는 앞에 SQL 명령어 중 데이터 조작어에서 살짝 다뤘습니다.
뒤에서 자세히 다루는 이유는 앞으로 많이 사용하기 때문인데요.
데이터를 분석할 때 Select는 여러 가지 절들과 함께 사용합니다.
대표적으로 from, where, group by, having, order by가 있습니다.
오늘 사용할 데이터는 insurance 데이터입니다.
앞서 R을 통한 회귀분석에서도 이 데이터를 사용했죠.
이제 Workbench에서 살펴보겠습니다.
데이터 베이스 사용
/* 데이터베이스 da 사용 */
use da;데이터 베이스 da를 사용하겠습니다.
데이터 불러오기

왼쪽의 da 데이터베이스에 마우스 오른쪽을 클릭하면
Table Data import Wizard가 뜹니다.
누르시면
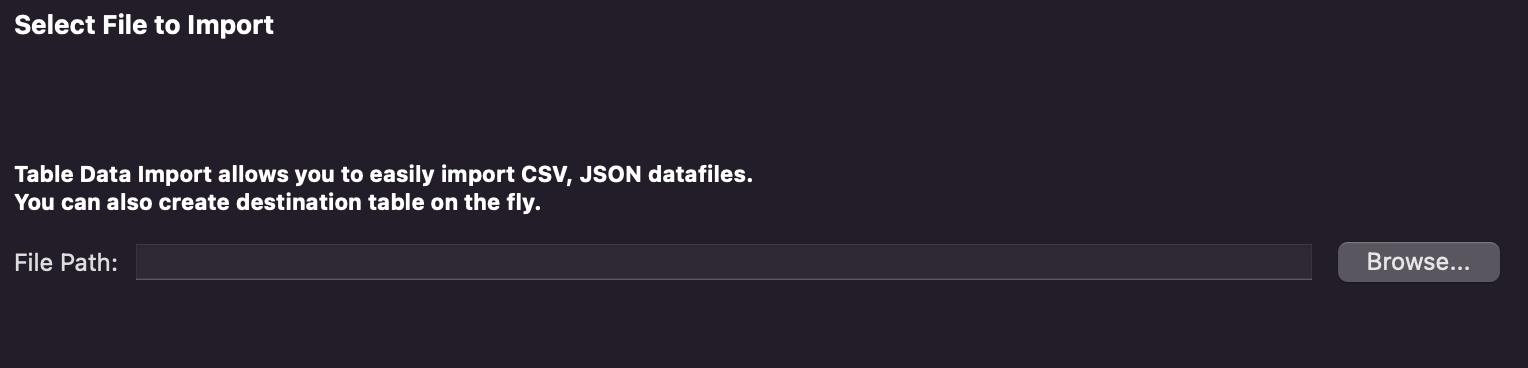
이러한 화면이 뜨는데 여기서 Browse를 클릭하시면
데이터를 불러올 수 있습니다.
매우 간단합니다.
이제 데이터를 조회해볼게요.
/* insurance 테이블 모든 열 조회 */
select * from insurance;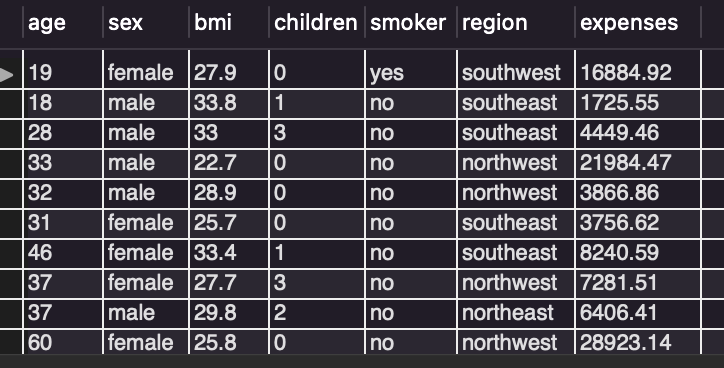
제대로 불러와진 것을 확인할 수 있습니다.
변수에는 age인 나이, sex엔 성별, bmi 지수
children에는 자녀의 수, smoker에는 흡연 여부
region에는 사는 지역, expenses에는 비용이 있습니다.
오늘은 여기서 region, smoker 변수를 사용해보겠습니다.
Select와 Where을 통한 필터링
/* 흡연을 하는 사람으로 필터링 */
select * from insurance
where smoker = 'yes';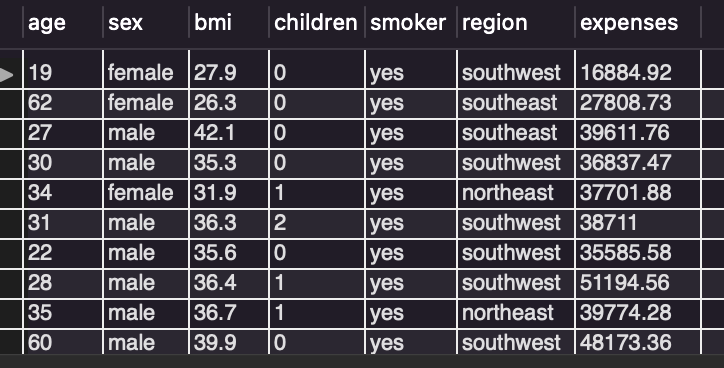
select * from을 통해 모든 변수를 테이블에 가져오면서
where에 smoker = 'yes'를 추가하여
흡연자 데이터만을 필터링하여 가져왔습니다.
이번에는 group by를 통하여 지역별 흡연자 수를 알아볼게요.
Group by를 통한 그룹화
/* 지역별 흡연자 수 */
select region, count(smoker) as 흡연자수
from insurance
where smoker = 'yes'
group by region;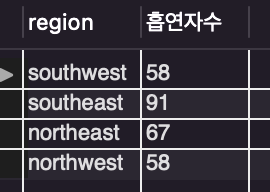
select region을 통해 region변수를 불러오고
count라는 집계 함수에 smoker를 집어넣고
흡연자수라는 열을 추가로 만들어줬습니다.
이렇게 되면 smoker 변수 모든 데이터 개수를 count 해줍니다.
여기서 앞서 보여드린 것처럼 where로 흡연자만을 가져오면
smoker변수 중 흡연자의 데이터 수만 보여지므로
흡연자 데이터 수가 count 됩니다.
그다음 group by로 region으로 그룹화해주시면 됩니다.
여기서 중요한 것은 select에서 불러온 변수랑
group by에서 쓰는 변수를 통일해서 작성해줘야 하는 점입니다.
이번에는 흡연자 수에 따라 조건을 걸고 필터링을 해주겠습니다.
Having을 통한 조건 필터링
/* 지역별 흡연자 수 90명 미만으로 필터링 */
select region, count(smoker) as 흡연자수
from insurance
where smoker = 'yes'
group by region
having count(smoker) < 90;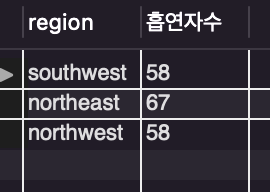
having을 통해 흡연자 수가 90보다 작은 행으로만
조건을 붙여 필터링을 해줬습니다.
이제는 흡연자 수에 따라 내림이나 오름차순으로 정렬해볼까요?
Order by를 통한 정렬
/* 지역별 흡연자 수 90명 미만으로 높은 순서대로 필터링 */
select region, count(smoker) as 흡연자수
from insurance
where smoker = 'yes'
group by region
having count(smoker) < 90
order by count(smoker) desc;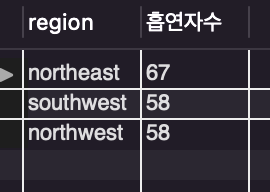
order by에 desc를 넣어 흡연자 수에 따라 내림차순으로 정렬시켰습니다.
desc는 descend의 줄임말입니다.
그렇다면 오름차순 정렬도 해야겠죠?
오름차순은 ascend의 줄임말인 asc를 넣어주면 됩니다.
/* 지역별 흡연자 수 90명 미만으로 낮은 순서대로 필터링 */
select region, count(smoker) as 흡연자수
from insurance
where smoker = 'yes'
group by region
having count(smoker) < 90
order by count(smoker) asc;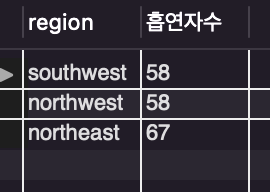
오름차순으로 정렬된 것이 보이죠.
여기까지가 여러 가지 절을 추가하여
select를 통한 필터링을 다뤘습니다.
마지막은 조금 응용하여 지역별로 흡연자의 수 뿐만 아니라
흡연 여부와 그에 해당하는 인원수를 테이블로 구현해보겠습니다.
활용
/* 지역별 흡연자와 비흡연자 수 */
select region, smoker, count(smoker) as 해당수
from insurance
where smoker in ('yes', 'no')
group by region, smoker;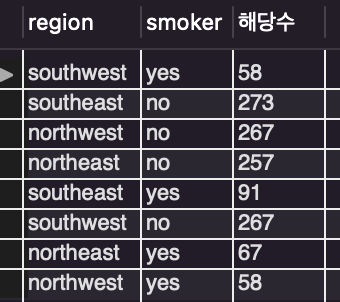
select로 region와 smoker를 불러왔습니다.
그리고 마찬가지로 smoker를 count 해줬습니다.
그리고 as를 통해 흡연자수가 아닌 해당수라고 작성하여
흡연자 수와 비흡연자 수를 둘 다 표현하고자 했습니다.
그리고 이번에는 where에 특수 연산자 in을 활용하여
smoker의 yes와 no를 리스트로 넣어 둘 다 필터링했습니다.
마지막으로 group by를 통해 region과 smoker로 그룹화를 시켰습니다.
이렇게 보니 위에서는 지역별 흡연자 수만 볼 수 있었는데
이제는 비흡연자 수도 같이 볼 수 있습니다.
하지만 지역이 섞여있어 보기에 불편함이 있습니다.
위에서 활용했던 order by를 통해 지역을 정렬해볼까요?
/* 지역별 흡연자와 비흡연자 수 정렬 */
select region, smoker, count(smoker) as 해당수
from insurance
where smoker in ('yes', 'no')
group by region, smoker
order by region desc;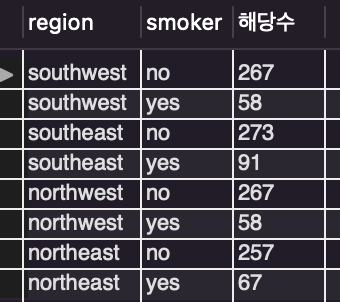
이제 지역별로 정렬이 된 모습을 볼 수 있습니다.
이렇게 select와 여러 가지 절을 잘 활용하면
우리가 보고 싶은 테이블을 만들어 데이터를 분석하기 쉽게 만들 수 있습니다.
다음에는 join을 통해 테이블을 결합하는 방법을 공부해보겠습니다!
'데이터분석 공부 > SQL' 카테고리의 다른 글
| [SQL] 비교 연산자, 논리 연산자 (0) | 2022.04.28 |
|---|---|
| [SQL] 테이블 결합 - JOIN (0) | 2022.04.27 |
| [SQL] 트랜젝션 제어어(TCL) (0) | 2022.04.20 |
| [SQL] 데이터 제어어(DCL) (0) | 2022.04.20 |
| [SQL] 데이터 조작어(DML) (0) | 2022.04.19 |



