
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Deep Learning Specialization
- IRIS
- sklearn
- 회귀분석
- 자격증
- 통계
- Google ML Bootcamp
- SQLD
- scikit learn
- 이코테
- matplotlib
- pandas
- ML
- 딥러닝
- 이것이 코딩테스트다
- 시각화
- Python
- 데이터 분석
- r
- 데이터분석준전문가
- tableau
- 코딩테스트
- ADsP
- SQL
- 머신러닝
- 데이터 전처리
- 데이터분석
- 파이썬
- pytorch
- 태블로
Archives
- Today
- Total
함께하는 데이터 분석
[R] dplyr 패키지 맛보기 본문
오늘은 통계 분석할 때 알아두면 편한 dplyr 패키지를 공부할 거예요!
이때 dplyr을 사용하지 않고 결과를 도출하는 코드와 dplyr을 사용하여 결과를 도출하는
2가지 방법 모두 코드를 올려놓을 테니 비교해 보는 재미도 있을 것 같아요!!
그럼 시작해볼까요?
| dplyr 함수 | 기능 |
| %>% | 함수 연결 |
| filter() | 행 추출 |
| select() | 열(변수) 추출 |
| arrange() | 정렬 |
| mutate() | 변수 추가 |
| summarise() | 통계량 산출 |
| group_by() | 집단별로 나누기 |
dplyr을 설치하는 방법
# dplyr 설치
install.packages("dplyr")만약 설치 오류가 난다면 Rstudio를 실행할 때 관리자 권한으로 실행을 누르세요
dplyr을 실행하는 방법
# dplyr 실행
library(dplyr)
이제 dplyr 기본 내장 데이터인 starwars 데이터를 불러올게요!
# dplyr starwars 데이터 불러오기
dplyr::starwars
열 이름 변경하기
# 열 이름 변경하기
sw1 <- starwars
colnames(sw1) # 1번째 name위치
names(sw1)[c(1)] <- c("이름")
head(sw1)# dplyr 활용하여 열 이름 변경하기
sw2 <- starwars %>% rename(이름 = name)
head(sw2)
원하는 열만 추출하기
# "name", "height" 열만 추출하기
sw3 <- starwars[,c("name", "height")]
head(sw3)# dplyr을 이용하여 "name", "height" 열만 추출하기
sw4 <- starwars %>% select(name, height)
head(sw4)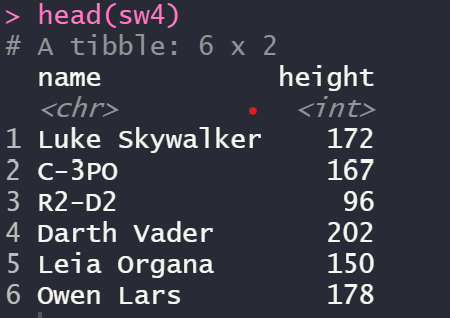
특정 조건을 결합해 조건에 부합하는 행(rows)을 추출
# 특정 조건을 걸어 조건에 부합하는 행 추출
sw5<- subset(starwars, height > 160)
head(sw5)
table(sw5$height)sw6 <- starwars %>% filter(height > 160)
head(sw6)
table(sw6$height)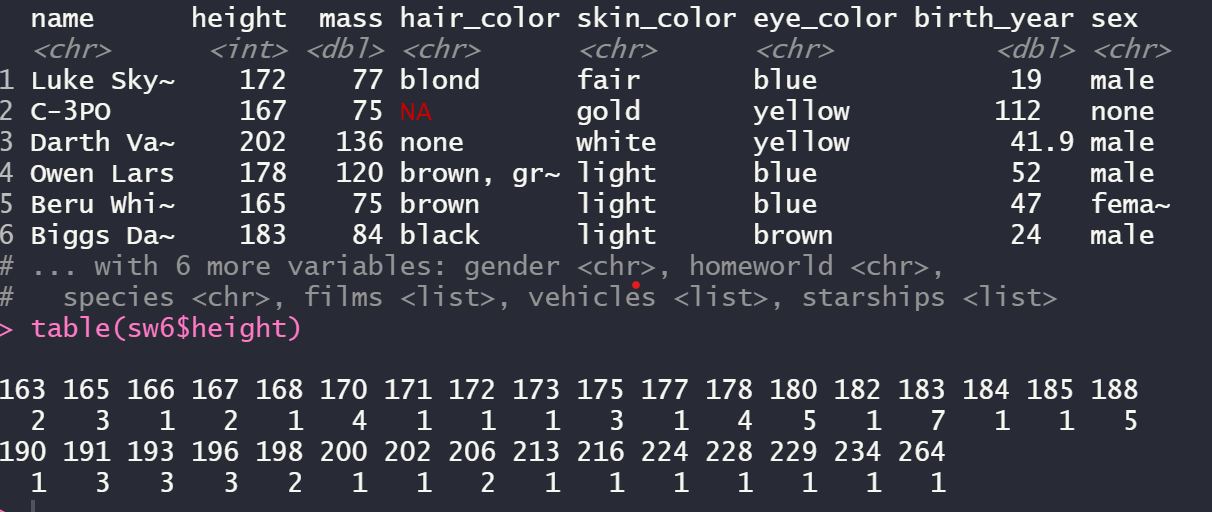
기존의 열을 이용해 새로운 열을 생성
sw7 <- starwars[,c("name", "height")]
head(sw7)
sw7$celebrity <- ifelse(sw7$height>180, "winner", "loser")
head(sw7)# dplyr을 이용하여 기존의 열을 이용해 새로운 열을 생성
sw8 <- starwars %>% select(name, height) %>%
mutate(celebrity=ifelse(height>180, "winner", "loser"))
head(sw8)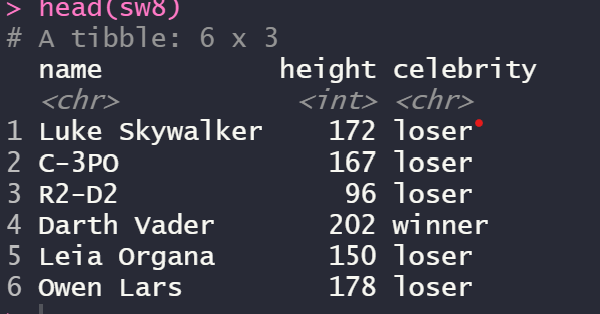
특정 열을 기준으로 오름 또는 내림차순 정렬
# 정렬하기(오름차순, 내림차순)
sw9 <- sw8[order(sw8$height),]
head(sw9)
sw9_1 <- sw8[order(sw8$height, decreasing=T),] #내림차순
head(sw9_1)# dplyr을 이용하여 정렬하기(오름차순, 내림차순)
sw10 <- sw8 %>% arrange(height)
head(sw10)
sw11 <- sw8 %>% arrange(desc(height)) #desc는 내림차순
head(sw11)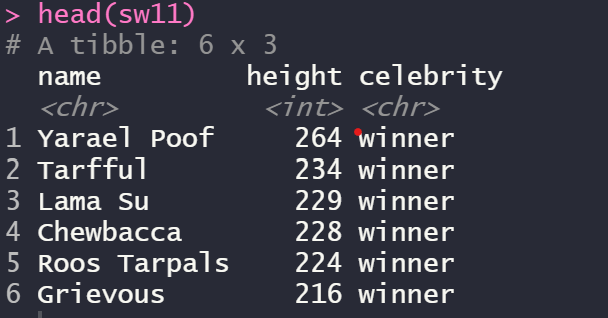
데이터 요약 통계량
| 함수 | 기능 |
| n() / n_distinct() | 갯수 / 중복 제거 후 갯수 |
| min() | 최소 |
| max() | 최대 |
| sum() | 합 |
| mean() | 평균 |
| var() | 분산 |
| sd() | 표준편차 |
| median() | 중위수 |
# 요약 통계량 구하기
# 키 평균 구하기
mean_sw0 <- mean(starwars$height, na.rm=T)
round(mean_sw0, 0)# dplyr을 이용하여 요약 통계랑 구하기
# 키 평균 구하기
mean_sw1 <- starwars %>%
summarise(meanheight=mean(height, na.rm=T))
head(mean_sw1)# 성별 열의 종류
kd_sw1 <- starwars %>%
summarise(kind_gender=n_distinct(gender))
kd_sw1
unique(starwars$gender)
그룹화하여 연산
#gender의 갯수를 알려주는 방법
gendercount <- table(starwars$gender, useNA='ifany')
gendercount# dplyr을 이용하여 그룹화하고
# gender로 그룹화 후 각 gender의 갯수를 알려주는 열 생성
gr_sw2 <- starwars %>%
group_by(gender) %>% summarise(gendercount=n())
gr_sw2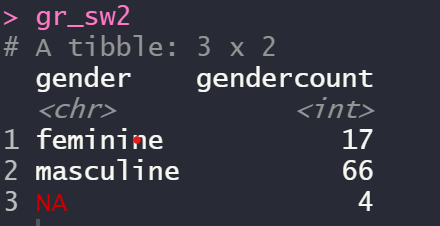
데이터 요약 통계량과 그룹화 하는 것은 dplyr을 사용했을 때와 하지 않았을 때 약간은 다르지만
큰 틀은 비슷해서 참고하시라고 코드 올렸습니다!
dplyr을 사용했을 때 파이프라인인 %>%을 이용해서 일관적으로 편하게 코드를 작성할 수 있는 것을
확인하실 수 있습니다!
그럼 마치겠습니다!!

'데이터분석 공부 > R' 카테고리의 다른 글
| [R] 이상치(outlier)와 결측치(missing value) 처리하기 (0) | 2022.01.20 |
|---|---|
| [R] ggplot2 패키지로 그래프 그리기 (2) | 2022.01.20 |
'데이터분석 공부/R' Related Articles
more

