
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 코딩테스트
- 파이썬
- 데이터분석
- 이것이 코딩테스트다
- 태블로
- 딥러닝
- 이코테
- 데이터분석준전문가
- 데이터 분석
- pandas
- 데이터 전처리
- matplotlib
- tableau
- ADsP
- pytorch
- ML
- 머신러닝
- SQLD
- Google ML Bootcamp
- 자격증
- sklearn
- r
- Deep Learning Specialization
- scikit learn
- 통계
- SQL
- 시각화
- 회귀분석
- IRIS
- Python
Archives
- Today
- Total
함께하는 데이터 분석
[EDA] K-Means Clustering with R 본문
안녕하세요!
오늘은 EDA수업에서 배우는 또 다른 Clustering 기법인
k-means clustering을 R을 통해 알아보겠습니다.
간단한 좌표 설정
set.seed(1234) #rnorm으로 생성된 값 계속쓰기 위해 고정
x <- rnorm(12, mean=rep(c(1, 2, 3), each = 4), sd=rep(0.2, 12))
y <- rnorm(12, mean=rep(c(1, 2, 1), each = 4), 0.2)
plot(x, y, col = "blue", pch = 19, cex = 2)
text(x + 0.05, y + 0.05, labels = as.character(1:12))
Kmeans() 이용하기
dataFrame <- data.frame(x, y)
kmeansObj <- kmeans(dataFrame, centers = 3) # k-means with k=3
table(kmeansObj$cluster)
>>> 1 2 3
4 4 4
kmeansObj$cluster
>>> [1] 3 3 3 3 1 1 1 1 2 2 2 2
points(x, y, col = kmeansObj$cluster, pch = 19, cex = 2)
image() 이용하기
par(mfrow=c(1,2)) #그래픽 1행 2열로 보이게
image(t(dataFrame)[, nrow(dataFrame):1], yaxt = "n", main = "Original Data")
image(t(dataFrame)[, order(kmeansObj$cluster)], yaxt = "n", main = "Clustered Data")
Silhouette 이용하기
library(cluster)
data.dist<-dist(dataFrame)
par(mfrow=c(1,3))data.km2<-kmeans(dataFrame, centers=2)
data.km2.sil<-silhouette(data.km2$cl, data.dist)
plot(data.km2.sil, main="K-means with k=2")
data.km3<-kmeans(dataFrame, centers=3)
data.km3.sil<-silhouette(data.km3$cl, data.dist)
plot(data.km3.sil, main="K-means with k=3")
data.km4<-kmeans(dataFrame, centers=4)
data.km4.sil<-silhouette(data.km4$cl, data.dist)
plot(data.km4.sil, main="K-means with k=4")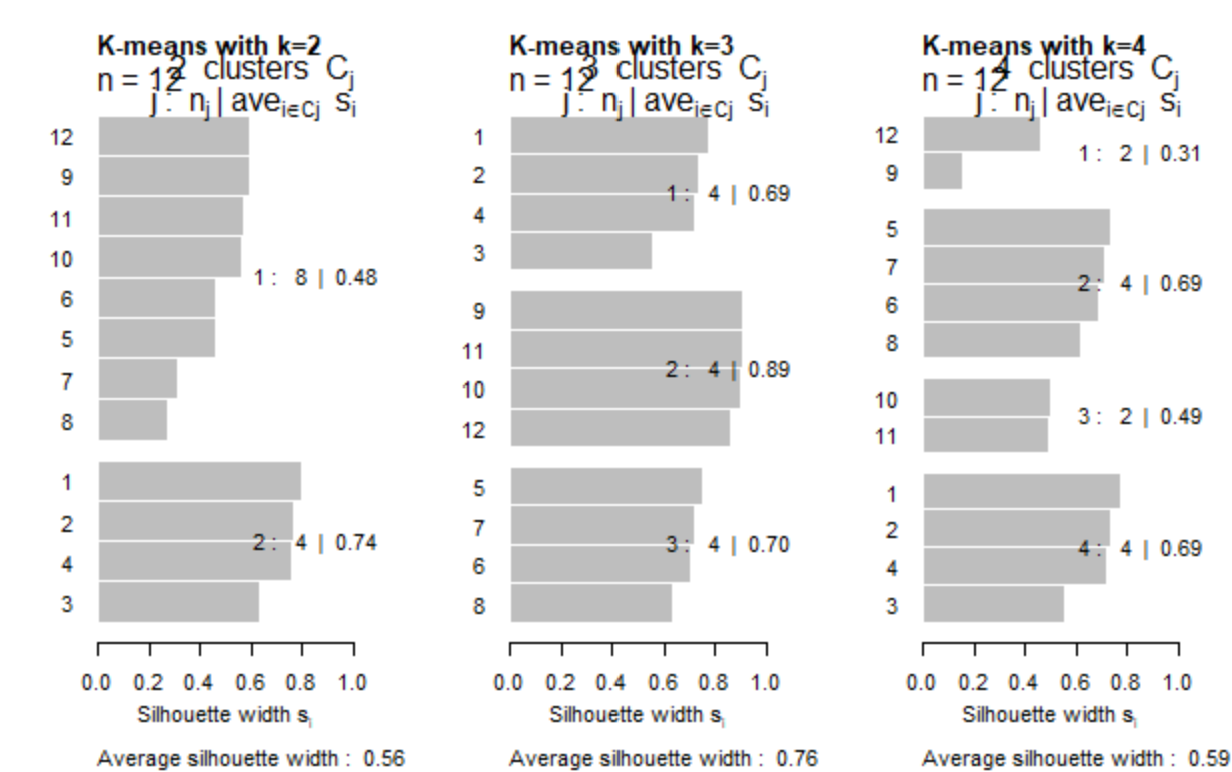
k=2일때 0.56, k=3일때 0.76, k=4일때 0.59로
k=3인 3개의 cluster로 분류할 때 0.76으로 가장 높은 결과를 도출하는 것을 알 수 있습니다!
감사합니다!

'통계학과 수업 기록 > EDA' 카테고리의 다른 글
| [EDA] FA with R (0) | 2022.02.06 |
|---|---|
| [EDA] PCA with R (0) | 2022.02.06 |
| [EDA] SVD with R (0) | 2022.02.05 |
| [EDA] Hierarchical Clustering with R (0) | 2022.02.02 |
'통계학과 수업 기록/EDA' Related Articles
more



