
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pytorch
- 이코테
- SQLD
- 데이터 분석
- 이것이 코딩테스트다
- 코딩테스트
- 통계
- ML
- IRIS
- 데이터분석준전문가
- pandas
- 머신러닝
- 데이터분석
- tableau
- Python
- sklearn
- 태블로
- 데이터 전처리
- r
- 자격증
- Deep Learning Specialization
- ADsP
- Google ML Bootcamp
- scikit learn
- matplotlib
- 파이썬
- 회귀분석
- 딥러닝
- 시각화
- SQL
- Today
- Total
함께하는 데이터 분석
[R] 선형회귀를 이용한 회귀분석 본문
안녕하세요!
오늘은 선형회귀를 이용한 의료비 예측하는 간단한 예제를 살펴볼게요.
위 파일을 사용할 것입니다.
| 변수명 | 변수설명 |
| Age | 주 수익자의 연령, 정수(64세 이상은 일반적으로 정부에서 관리하기 때문에 제외) |
| Sex | 보험 계약자의 성별, 여성 또는 남성 |
| Bmi | 몸무게(kg)을 키(m)의 제곱으로 나눈 값 |
| Children | 의료보험이 적용되는 자녀 수/부양가족 수. 정수 |
| Smoker | 피보험자의 정기적인 흡연 여부, 예 또는 아니오, 범주형 변수 |
| Region | 사는 지역, 범주형 변수 |
| Expenses | 종속변수 |
위의 표가 변수에 관한 설명입니다.
이제 시작해볼까요?
1. 데이터 불러오기
setwd("경로")
insurance <- read.csv("insurance.csv", stringsAsFactors = T)stringsAsFactors = T는 범주형 변수가 포함된 데이터를 불러올 때 사용하시면 됩니다!
2. 데이터 확인하기
dim(insurance)
>>> [1] 1338 7
head(insurance)
>>> age sex bmi children smoker region expenses
1 19 female 27.9 0 yes southwest 16884.92
2 18 male 33.8 1 no southeast 1725.55
3 28 male 33.0 3 no southeast 4449.46
4 33 male 22.7 0 no northwest 21984.47
5 32 male 28.9 0 no northwest 3866.86
6 31 female 25.7 0 no southeast 3756.62
str(insurance)
>>> 'data.frame': 1338 obs. of 7 variables:
$ age : int 19 18 28 33 32 31 46 37 37 60 ...
$ sex : Factor w/ 2 levels "female","male": 1 2 2 2 2 1 1 1 2 1 ...
$ bmi : num 27.9 33.8 33 22.7 28.9 25.7 33.4 27.7 29.8 25.8 ...
$ children: int 0 1 3 0 0 0 1 3 2 0 ...
$ smoker : Factor w/ 2 levels "no","yes": 2 1 1 1 1 1 1 1 1 1 ...
$ region : Factor w/ 4 levels "northeast","northwest",..: 4 3 3 2 2 3 3 2 1 2 ...
$ expenses: num 16885 1726 4449 21984 3867 ...
summary(insurance$expenses)
>>> Min. 1st Qu. Median Mean 3rd Qu. Max.
1122 4740 9382 13270 16640 63770의료비의 4분위수를 확인한 결과
Median보다 Mean이 큰 것으로 보아 오른쪽 꼬리가 긴 분포를 따를 것이라고
추측할 수 있습니다.
hist(insurance$expenses)
3. 독립변수와 종속변수 간 산점도와 상관계수 확인
library(psych)
pairs.panels(insurance[c("age", "bmi", "children", "expenses")])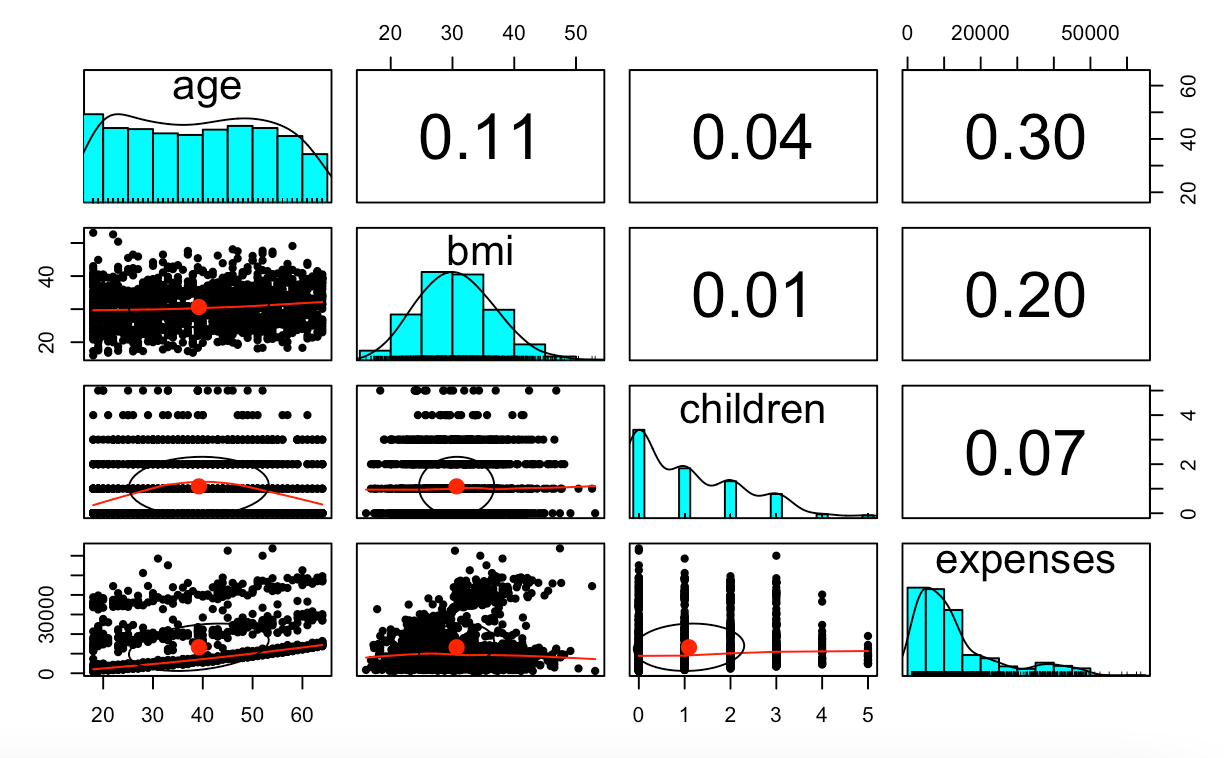
psych 라이브러리를 이용하면 산점도와 상관계수를 동시에 확인할 수 있습니다!
모든 변수간의 약한 양의 상관관계를 갖고 그중 age와 expenses 변수 간의
상관관계가 가장 강하다는 것을 알 수 있습니다.
4. 모든 변수를 포함한 회귀 모형 수립
ins_model1 <- lm(expenses ~ age + sex + bmi +
children + smoker + region, data = insurance)
## 모든 변수를 할시 똑같음
## ins_model1 <- lm(expenses ~ ., data = insurance)
summary(ins_model1)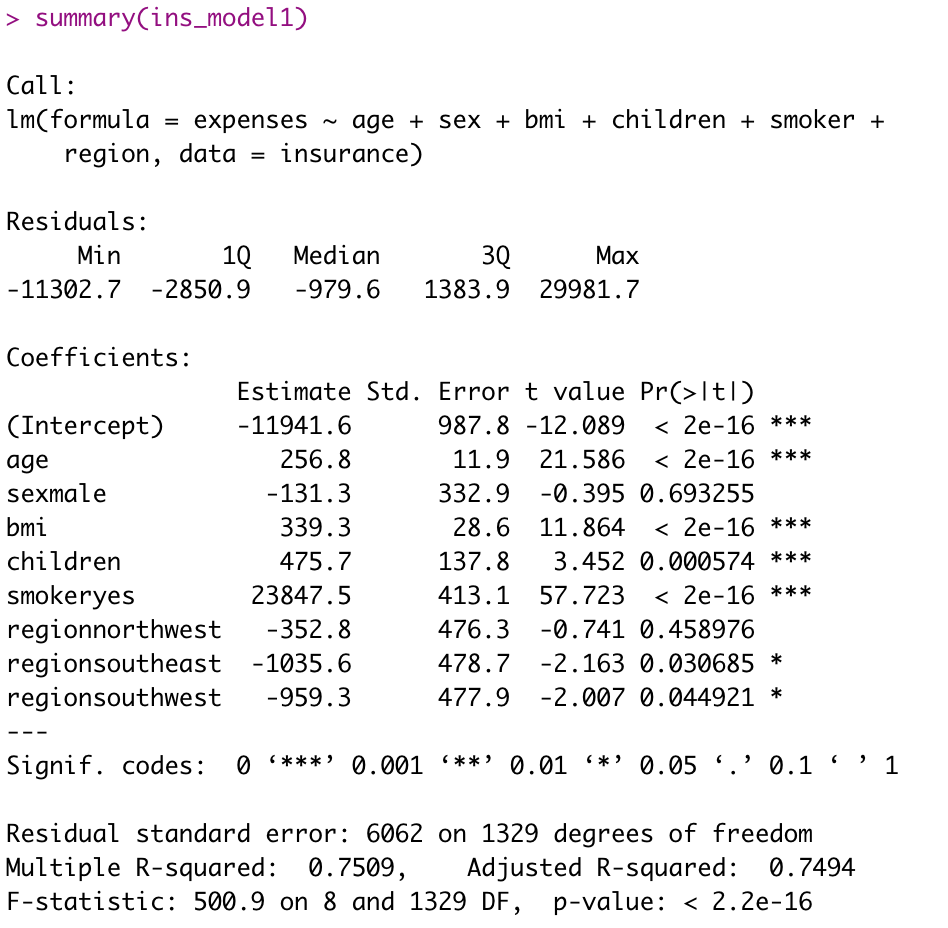
우선 변수의 p-value를 살펴보면 유의 수준 알파를 0.05라고 가정할 때
sexmale, regionnorthwest 변수가 유의 수준보다 작으므로 회귀분석을 할 때
적절하지 못한 변수라는 것을 볼 수 있습니다.
그리고 결정계수(R^2)와 조정결정계수를 살펴보면 대략 0.75 정도입니다.
결정계수는 0.75 이상이면 좋은 선형 관계를 나타낸다고 볼 수 있고
그 값이 1에 가까울수록 좋습니다.
마지막으로 F통계량의 p-value값이 0.05보다 작으므로
회귀 식이 유의하다고 볼 수 있습니다.
5. 더 좋은 회귀모형 수립
insurance$age2 <- insurance$age^2
insurance$bmi30 <- ifelse(insurance$bmi >= 30, 1, 0)
ins_model2 <- lm(expenses ~ age + age2 + sex + bmi +
children + bmi30*smoker + region, data = insurance)age변수 외에 age의 제곱 변수를 추가하고
bmi를 30 이상이면 1, 30 미만이면 0으로 설정하고
회귀분석 모형을 설정할 때 bmi와 smoker변수가 상관관계가 있다고 판단하여
둘을 결합한 새로운 파생변수를 만들었습니다.
summary(ins_model2)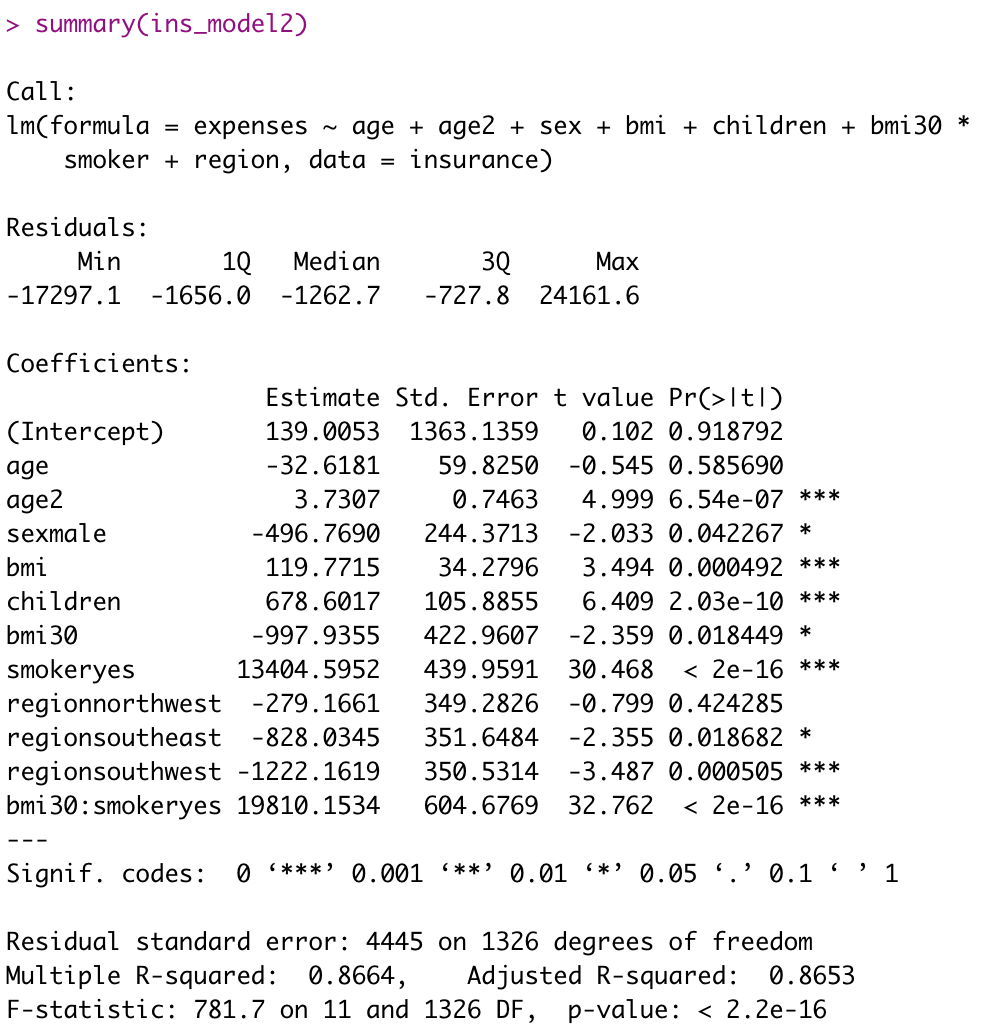
살펴보면 모든 독립변수의 p-value가 0.05보다 작고
결정계수가 0.86으로 더 커졌고
F통계량의 p-value가 0.05보다 작으므로
더 좋은 회귀모형이라고 할 수 있습니다.
회귀식은 expenses = 139.0053 - 32.6181*age + 3.7307*age2 ....입니다.
새로운 파생변수를 만들고 회귀모형을 만드는 것은
많은 시도를 해보고 값을 보며 비교하시면 될 것 같습니다.
여기까지입니다. 고생하셨어요!
Copyright
- 비어플 빅데이터 학회
'학회 세션 > 비어플' 카테고리의 다른 글
| [Classification] LDA(선형 판별분석) (0) | 2022.03.26 |
|---|---|
| [Python] IMAGE(2D data) AUGMENTATION (0) | 2022.03.24 |
| [R] 데이터 불균형 해소 (0) | 2022.03.20 |
| 데이터 불균형 해소 (0) | 2022.03.20 |
| [R] 토픽모델링 (0) | 2022.02.19 |



