
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 회귀분석
- scikit learn
- pytorch
- 머신러닝
- IRIS
- 시각화
- 자격증
- SQL
- 데이터분석준전문가
- 딥러닝
- matplotlib
- 코딩테스트
- Deep Learning Specialization
- Python
- sklearn
- tableau
- Google ML Bootcamp
- 파이썬
- pandas
- 데이터 분석
- 이것이 코딩테스트다
- r
- 데이터 전처리
- SQLD
- 태블로
- 통계
- ML
- ADsP
- 데이터분석
- 이코테
Archives
- Today
- Total
함께하는 데이터 분석
데이터 불균형 해소 본문
안녕하세요!
오늘은 데이터가 불균형이어서 우리가 모델링을 할 때
유의미한 결과값을 얻을 수 없을 때 어떻게 대처해야 하는지를
알아보겠습니다.
예를 들면 종양의 악성 유무를 살펴보면 100명 중 1명이 악성이라고 할 때
어떻게 보면 굉장히 적은 수치이지만 1명의 경우 심각한 상황을 초래하기 때문에
정확히 예측하는 것이 중요하죠.
이때 99명이 종양이 없고 1명이 악성이라 하면 나머지 많은 데이터를 예측할 때
종양이 없다고 예측하면 99%의 정확도를 갖는 상황이 발생할 수 있습니다.
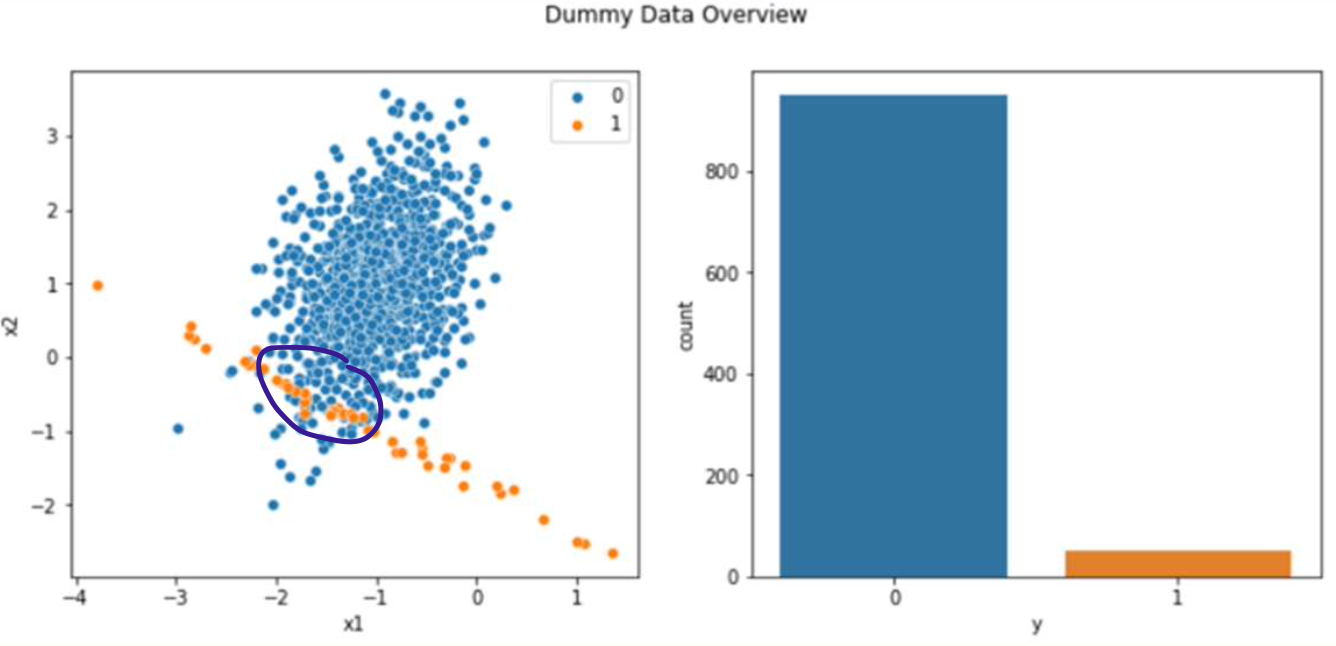
이렇게 차이가 나는 데이터라고 가정하면
어떠한 모형이냐에 따라 다르겠지만 보라색 부분의 y = 1인 값들은
아마도 0으로 분류될 확률이 높을 것입니다.

따라서 우리는 이러한 불균형을 해소하기 위한 2가지 방법을 알아보려 합니다.
불균형을 해소한다는 말이 곧 데이터의 개수를 비슷하게 맞춰준다고 하면
이해하기 편하실 텐데요.
y=1을 y=0으로 맞춰주는 즉, 많은 것을 작은 것에 맞춰주는 언더샘플링
작은 것을 큰 것에 맞춰주는 오버샘플링이 있습니다.
언더샘플링
- Random undersampling : 우리가 random sample을 쉽게 만들어서 개수를 맞춰주는 방법입니다. 이때 랜덤으로 생성된 값들이 원래 분포를 잘 대변할 수 있냐에는 살짝 물음표가 있을 수 있죠.
- Tomek links : 위의 Random undersampling의 원래 분포를 대변하기 힘든 문제점을 해결하기 위한 방안 중 하나인데, y=0과 y=1의 다른 값 중 붙어있는 값 즉 분포의 특성이 가장 옅다고 생각할 수 있는 값을 우선적으로 제거해주는 방법입니다. 하지만 Tomek link의 개수만큼만 제거되므로 개수를 조금밖에 못 맞춰줄 수도 있다는 단점이 존재합니다.
하지만 궁극적으로 불균형을 해소하고 데이터의 용량을 감소시켜준다는 장점이 존재하지만,
데이터(정보)의 손실이 발생하기 때문에 많이 활용되지는 않습니다.
오버샘플링
- Resampling : 있는 개수가 적은 데이터를 여러 번 사용해서 개수를 맞춰주는 방법입니다. 하지만 있는 데이터를 반복하여 학습하는 경우이기에 상황에 따라 좋을 수도 나쁠 수도 있어서 경우에 맞게 잘 활용해야 합니다.
- 가우시안 노이즈 : 약간의 노이즈를 줘서 개수를 맞춰주는 방법입니다.
- SMOTE : 데이터와 데이터 사이에 선분을 그어 그 내분점에 새로운 데이터를 생성하여 개수를 비슷하게 맞춰주는 방법입니다. 하지만 선분을 그어 만드는 것이므로 데이터들의 분포가 인위적으로 보일 수 있습니다.
다음 시간에는 간단한 R코드로 언더샘플링과 오버샘플링을
구현해보는 시간을 갖겠습니다.
감사합니다!
Copyright
- 비어플 빅데이터 학회
'학회 세션 > 비어플' 카테고리의 다른 글
| [Classification] LDA(선형 판별분석) (0) | 2022.03.26 |
|---|---|
| [Python] IMAGE(2D data) AUGMENTATION (0) | 2022.03.24 |
| [R] 데이터 불균형 해소 (0) | 2022.03.20 |
| [R] 선형회귀를 이용한 회귀분석 (0) | 2022.03.12 |
| [R] 토픽모델링 (0) | 2022.02.19 |
'학회 세션/비어플' Related Articles
more



