
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 코딩테스트
- pytorch
- 파이썬
- SQL
- 데이터 분석
- 딥러닝
- 데이터분석준전문가
- tableau
- 데이터 전처리
- sklearn
- 자격증
- IRIS
- SQLD
- pandas
- 머신러닝
- 통계
- 태블로
- 이것이 코딩테스트다
- ADsP
- ML
- 시각화
- scikit learn
- Python
- 회귀분석
- matplotlib
- Google ML Bootcamp
- 데이터분석
- r
- 이코테
- Deep Learning Specialization
- Today
- Total
함께하는 데이터 분석
[Ensemble] 머신러닝 앙상블 기법 본문
오늘은 머신러닝에서 자주 등장하는
앙상블 기법에 대해 알아볼게요!
우선 앙상블(Ensemble)이란
여러 개의 분류기를 생성하여 예측값을 종합하여 보다 정확한 예측값을 구하고
각각의 분류기를 사용했을 때의 단점을 보완해주는 기법입니다.
앙상블 기법에는 대표적으로 Voting, Bagging, Boosting이 있습니다.
이제 각각의 기법을 간단하게 살펴보겠습니다!
Voting
보팅에는 Hard Voting과 Soft Voting이 있습니다.

Hard Voting은 weak learner들의 예측값을
다수결의 원칙을 사용하여 나타내는 것입니다.
위의 사진을 보면 1을 예측한 분류기가 3개, 2를 예측한 분류기가 1개 이므로
다수결의 원칙에 따라 1로 예측하는 것입니다.
최빈값으로 결정한다고 할 수 있죠.
Soft Voting은 weak learner들의 예측값의 산술평균을 구하고
가장 높은 확률을 나타내는 클래스를 선택하여
최종 예측값으로 사용하는 것입니다.
Bagging
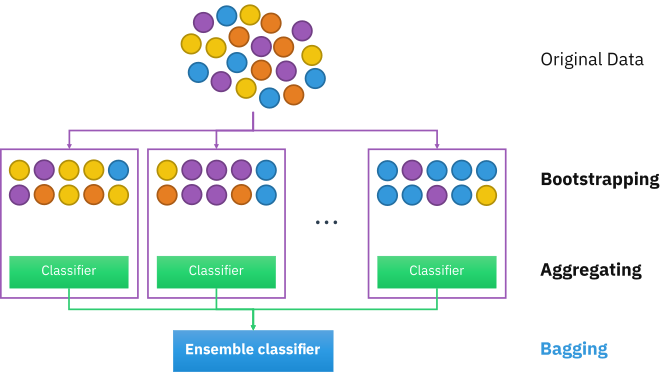
배깅은 Bootstrap Aggregating의 약자로
통계학을 공부하신 분들이라면 들어보셨을 만한 부트스트랩을 사용합니다.
부트스트랩은 주어진 데이터에서 복원 추출로 random sampling을 하는 기법입니다.
부트스트랩을 이용하여 만들어진 데이터를 기반으로 weak learner를 훈련시킨 뒤 보팅하는 기법입니다.
각각의 분류기들이 학습할 때 상호 영향을 주지 않는다는 특징이 있습니다.
장점으로는 예측의 분산을 줄여주므로 성능상의 이득을 주고
Overfitting의 대책으로 활용할 수 있다는 점입니다.
배깅의 대표적인 예시로 Random Forest가 있습니다.
Boosting

부스팅은 배깅과 유사한 메커니즘을 갖고 있습니다.
하지만 배깅과의 차이점이라면 순차적으로 학습이 진행됩니다.
즉, 배깅은 각각의 분류기들이 학습할 때 상호 영향을 주지 않는다고 한다면
부스팅은 이전 분류기의 학습 결과를 토대로 다음 분류기의 학습에 샘플 가중치를 두어
학습을 진행한다는 특징이 있습니다.
부스팅은 오답인 경우에 높은 가중치를 두어 학습하므로 정확도가 높게 나타나지만,
Outlier에 민감할 수 있다는 단점이 존재합니다.
부스팅의 대표적인 예시로는 AdaBoost, GradientBoost 등등이 있습니다.
'데이터분석 공부 > ML | DL' 카테고리의 다른 글
| [Scikit Learn] Random Forest (0) | 2022.08.28 |
|---|---|
| [Python] 시각화 / graphviz (0) | 2022.08.21 |
| [Scikit Learn] One-Hot Encoding (0) | 2022.05.13 |
| [Scikit Learn] Label Encoding (0) | 2022.05.13 |
| [Scikit Learn] Robust Scaling (0) | 2022.05.10 |



