
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Google ML Bootcamp
- r
- 자격증
- 코딩테스트
- 데이터분석
- 데이터 전처리
- Python
- 회귀분석
- 시각화
- 이것이 코딩테스트다
- 이코테
- SQLD
- 딥러닝
- 통계
- IRIS
- 파이썬
- sklearn
- ADsP
- SQL
- Deep Learning Specialization
- scikit learn
- 머신러닝
- pytorch
- matplotlib
- 데이터 분석
- 태블로
- pandas
- ML
- tableau
- 데이터분석준전문가
- Today
- Total
함께하는 데이터 분석
[Scikit Learn] One-Hot Encoding 본문
안녕하세요.
머신러닝을 돌리기 전 전처리 작업 중 하나인 인코딩에 대해 살펴볼게요.
전 포스트에서 말씀드렸기에 간단하게 설명한다면
인코딩은 문자형 변수를 수치형 변수로 변환해주는 것입니다.
저번 포스팅에서는 Label Encoding을 알아봤고
이번에는 One-Hot Encoding을 살펴볼게요.
One-Hot Encoding

머신러닝을 공부하신 분들이라면 한 번씩은 들어보셨을 One-Hot Encoding입니다.
One-Hot Encoding은 말 그대로
하나만 Hot하고 나머지는 Cold 한다는 뜻입니다.
새로운 칼럼을 추가하여 해당하는 칼럼에만 1을 표시하고
나머지 칼럼에는 0을 표시합니다.
이제 Python을 통해 One-Hot Encoding을 진행해보겠습니다.
라이브러리 불러오기
import numpy as np
import pandas as pd
import seaborn as sns
import sklearn
import warnings
warnings.filterwarnings('ignore')numpy와 pandas는 데이터 분석을 할 때 default로 불러오는 라이브러리이고
seaborn은 mpg 데이터를 활용하기 위해 불렀습니다.
sklearn이 오늘 인코딩을 할 때 사용할 라이브러리이고
warnings는 경고창을 보여주지 않기 위해 불러왔습니다.
데이터 불러오기 및 정제하기
mpg = sns.load_dataset('mpg')seaborn을 이용하여 mpg데이터를 불러왔습니다.
ori = mpg['origin']
ori.unique()
>>> array(['usa', 'japan', 'europe'], dtype=object)이번에는 간단하게 origin변수만을 가지고
ori라는 데이터를 만들어줬습니다.
ori데이터는 usa, japan, europe이라는 3개의 범주형 데이터가 존재합니다.
One-Hot Encoding
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()사이킷런의 preprocessing 패키지에 OneHotEncoder이 존재합니다.
앞 글자만 따서 ohe에 OneHotEncoder를 할당했습니다.
ori = ori.values.reshape((-1, 1))
oriohe = ohe.fit_transform(ori)ori데이터를 array타입으로 설정한 후 형식에 맞게 설정했습니다.
그리고 One-Hot Encoding을 진행시킨 데이터를
oriohe에 할당시켰습니다.
oriohe
>>> <398x3 sparse matrix of type '<class 'numpy.float64'>'
with 398 stored elements in Compressed Sparse Row format>One-Hot Encoding을 진행시킨 oriohe데이터는
398x3의 sparse matrix형식으로 이루어져 있습니다.
따라서 toarray를 이용하여 표시하면
oriohe.toarray()
>>> array([[0., 0., 1.],
[0., 0., 1.],
[0., 0., 1.],
...,
[0., 0., 1.],
[0., 0., 1.],
[0., 0., 1.]])이렇게 array타입으로 수치형 데이터가 잘 인코딩 된 것을 확인할 수 있습니다.
이제 원래의 문자형 데이터와 인코딩 된 데이터를
하나의 데이터 프레임으로 합쳐보겠습니다.
columns = np.concatenate([np.array(['origin']), ohe.categories_[0]])
result = pd.DataFrame(data = np.concatenate([ori, oriohe.toarray()], axis = 1), columns = columns)column명을 기존의 origin과 ohe의 카테고리로 문자로 설정해준 다음
데이터 프레임으로 합쳤습니다.
제대로 됐는지 확인해보겠습니다.
result.head(20)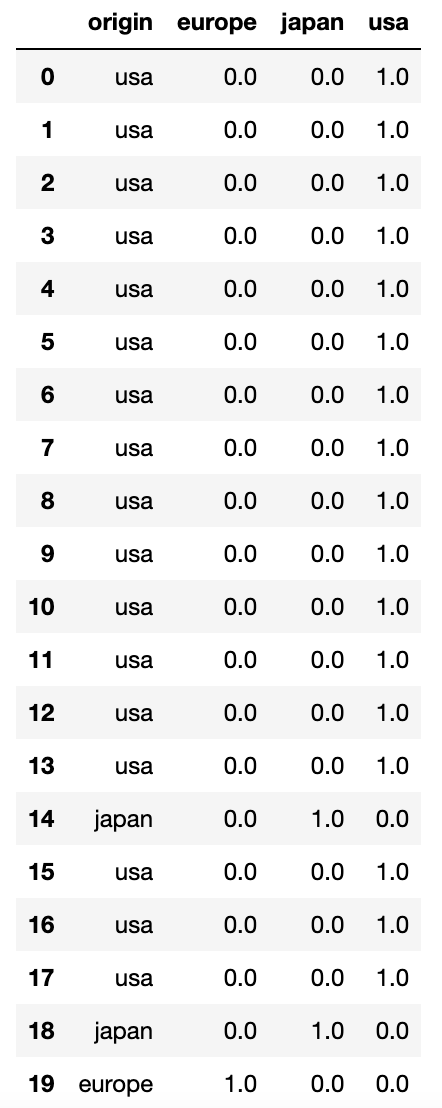
이렇게 제대로 One-Hot Encoding이 진행된 것을 확인할 수 있습니다.
만약 다시 문자형 데이터로 변환하고 싶다면 마찬가지로
ohe.inverse_transform(oriohe)
ohe.fit_transform 대신 ohe.inverse_transform을 사용해주시면 됩니다.
여기까지 One-Hot Encoding을 알아봤습니다!
'데이터분석 공부 > ML | DL' 카테고리의 다른 글
| [Python] 시각화 / graphviz (0) | 2022.08.21 |
|---|---|
| [Ensemble] 머신러닝 앙상블 기법 (0) | 2022.08.19 |
| [Scikit Learn] Label Encoding (0) | 2022.05.13 |
| [Scikit Learn] Robust Scaling (0) | 2022.05.10 |
| [Scikit Learn] MaxAbs Scaling (0) | 2022.05.10 |



