
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Deep Learning Specialization
- Python
- 딥러닝
- 머신러닝
- matplotlib
- Google ML Bootcamp
- tableau
- 통계
- pytorch
- ADsP
- 태블로
- 데이터분석
- sklearn
- SQLD
- scikit learn
- 데이터분석준전문가
- 자격증
- 이코테
- ML
- 데이터 분석
- IRIS
- pandas
- 코딩테스트
- 파이썬
- 데이터 전처리
- 회귀분석
- 시각화
- SQL
- r
- 이것이 코딩테스트다
- Today
- Total
함께하는 데이터 분석
[Scikit Learn] Label Encoding 본문
안녕하세요.
머신러닝을 돌리기 전 전처리 작업 중 하나인 인코딩을 살펴보겠습니다.
머신러닝 알고리즘은 대부분 문자형 데이터를 이해하지 못하므로
수치형 데이터로 인코딩하는 작업은 거의 필수적이라고 할 수 있습니다.
그래서 오늘은 사이킷런의 대표적인 두 가지 인코딩 방법 중
Label Encoding을 알아보겠습니다.
Label Encoding

Label Encoding은 어떤 피쳐의 n개의 범주형 데이터를
0 ~ n-1의 수치형 데이터로 변환합니다.
이때 이 변환 값이 수치적 차이를 나타내는 것은 아닙니다.
따라서 선형 회귀 등의 알고리즘에는 적용하는 것은 적합하지 않고
트리 계열의 알고리즘에는 적용해도 괜찮습니다.
이제 Python을 통해 Label Encoding을 살펴보겠습니다.
라이브러리 불러오기
import numpy as np
import pandas as pd
import seaborn as sns
import sklearn
import warnings
warnings.filterwarnings('ignore')numpy와 pandas는 데이터 분석을 할 때 default로 불러오는 라이브러리이고
seaborn은 mpg 데이터를 활용하기 위해 불렀습니다.
sklearn이 오늘 인코딩을 할 때 사용할 라이브러리이고
warnings는 경고창을 보여주지 않기 위해 불러왔습니다.
데이터 불러오기 및 정제하기
mpg = sns.load_dataset('mpg')
mpg.head()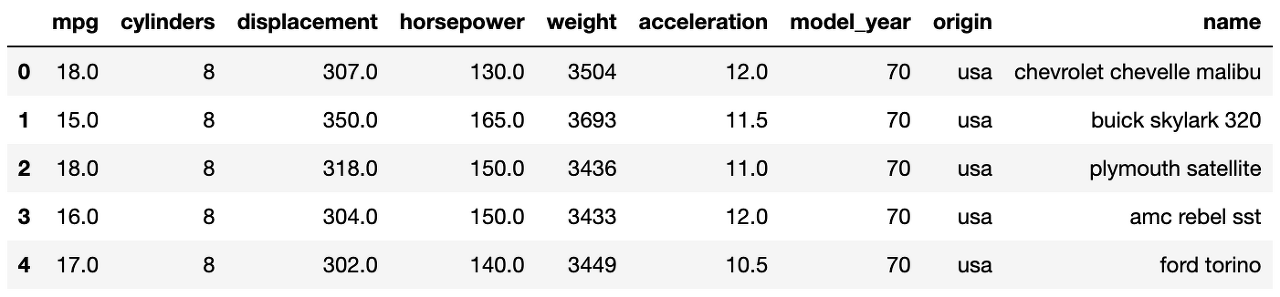
수치형 데이터를 스케일링 해줬던 전과는 달리
오늘은 문자형 데이터를 가져오겠습니다.
그중 origin 변수에 대해서 Label Encoding을 진행해볼게요.
ori = mpg['origin']
ori.unique()
>>> array(['usa', 'japan', 'europe'], dtype=object)origin변수에는 3개의 범주형 데이터가 존재합니다.
따라서 위의 설명대로면 0 ~ 2의 수치형 데이터로 변환할 것이라고 예측할 수 있습니다.
이제 본격적으로 Label Encoding을 진행해볼게요.
1개의 변수에 대한 Label Encoding
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()사이킷런의 preprocessing 패키지에 LabelEncoder이 존재합니다.
앞 글자만 따서 le에 LabelEncoder를 할당했습니다.
ori = ori.values.reshape((-1, 1))
orile = le.fit_transform(ori)ori 데이터를 array타입으로 설정한 후 형식에 맞게 설정했습니다.
그리고 Label Encoding을 진행시킨 데이터를
orile에 할당시켰습니다.
orile
이렇게 array타입으로 수치형 데이터가 인코딩 된 것을 확인할 수 있습니다.
마찬가지로 array타입을 형식에 맞게 설정해주겠습니다.
orile = orile.reshape((-1, 1))
result = pd.DataFrame(data = np.concatenate([ori, orile], axis = 1),
columns=['origin', 'origin_encoded'])
이제 원래의 문자형 데이터와 인코딩한 수치형 데이터를 비교해주기 위해
하나의 데이터 프레임으로 합쳤습니다.
확인해볼게요.
result.head(20)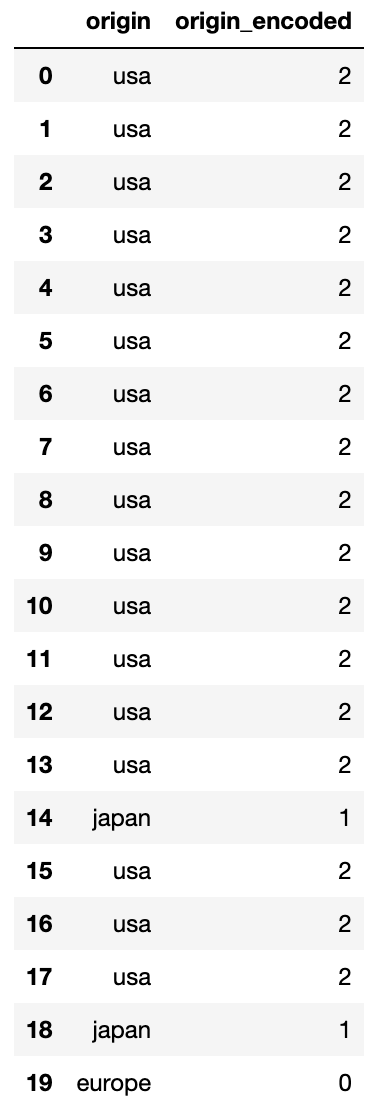
이렇게 제대로 인코딩 된 것을 확인했습니다.
만약 다시 문자형 데이터로 변환하고 싶다면
le.inverse_transform(orile)
fit_transform이 아닌 inverse_transform을 이용하여
다시 문자형 데이터로 변환해주면됩니다.
이제 2개 이상의 변수에 대한 Label Encoding을 진행해보겠습니다.
2개 이상의 변수에 대한 Label Encoding
mpg = sns.load_dataset('mpg')다시 mpg 데이터를 불러왔습니다.
categorical_feats = mpg.dtypes[mpg.dtypes == "object"].index.tolist()
categorical_feats
>>> ['origin', 'name']mpg데이터에서 범주형 변수를 뽑아줬습니다.
전 포스팅에서 봤던 대로 origin과 name변수입니다.
mpg1 = mpg[categorical_feats]
mpg2 = mpg[categorical_feats]
mpg데이터에 범주형 변수만을 인덱싱하여
똑같은 mpg1, mpg2 데이터를 생성해줬습니다.
이유는 하나의 데이터는 인코딩을 하고 하나의 데이터는 그대로 둔 다음
두 개의 데이터를 하나의 데이터 프레임으로 합쳐 확인하기 위함입니다.
for i in categorical_feats :
le = LabelEncoder()
mpg1[i] = le.fit_transform(mpg1[i])for문을 통해 mpg1의 데이터의 2개의 범주형 변수에 대한
Label Encoding을 진행했습니다.
이제 하나의 데이터프레임으로 합쳐 확인해보겠습니다.
result = pd.DataFrame(data = np.concatenate([mpg2, mpg1], axis = 1),
columns = ['origin', 'name', 'origin_encoded', 'name_encoded'])
result.head(20)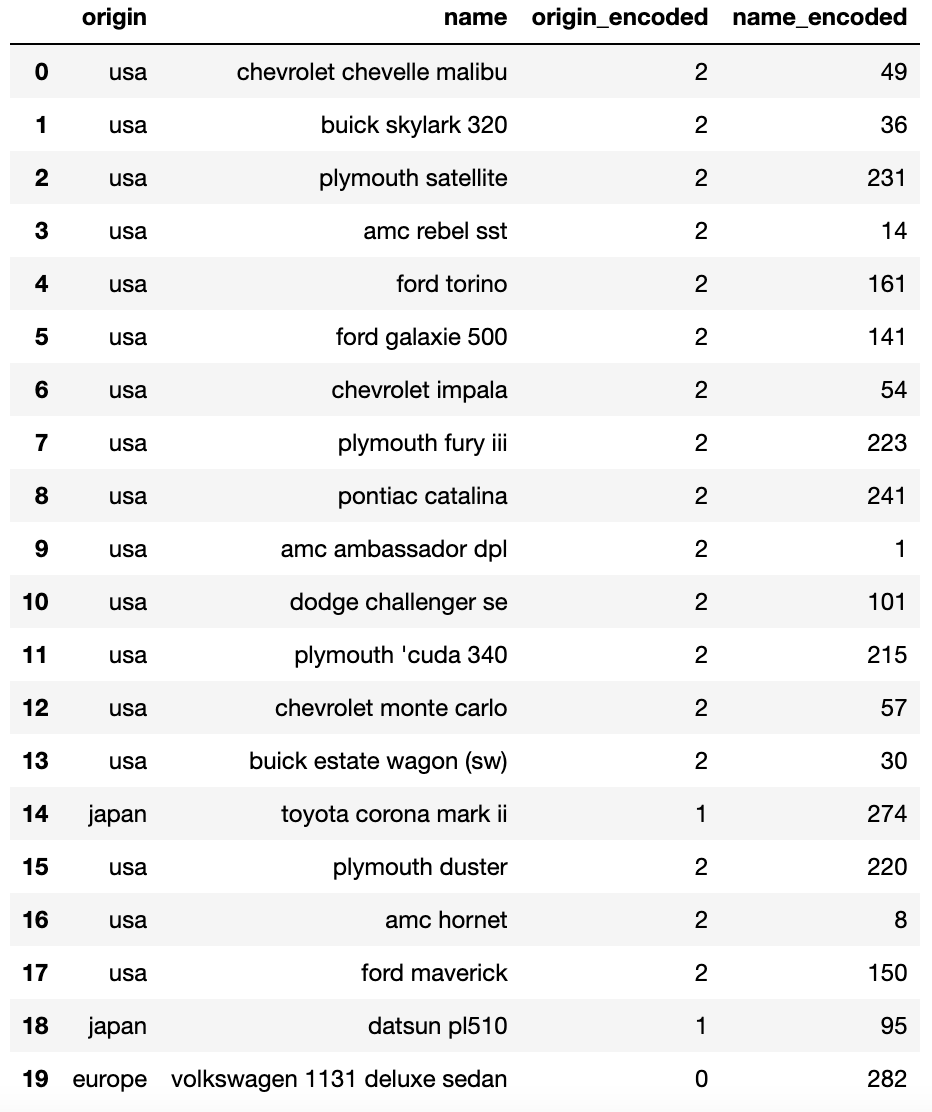
제대로 인코딩 된 것을 확인할 수 있습니다.
다음에는 사이킷런의 인코딩 방법 중 하나인
One-Hot Encoding을 진행해보겠습니다!
'데이터분석 공부 > ML | DL' 카테고리의 다른 글
| [Ensemble] 머신러닝 앙상블 기법 (0) | 2022.08.19 |
|---|---|
| [Scikit Learn] One-Hot Encoding (0) | 2022.05.13 |
| [Scikit Learn] Robust Scaling (0) | 2022.05.10 |
| [Scikit Learn] MaxAbs Scaling (0) | 2022.05.10 |
| [Scikit Learn] Min-Max Scaling (1) | 2022.05.10 |



