
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 데이터 분석
- 회귀분석
- 자격증
- 태블로
- 파이썬
- pytorch
- 데이터분석
- 이코테
- ADsP
- 데이터분석준전문가
- matplotlib
- Deep Learning Specialization
- scikit learn
- tableau
- Google ML Bootcamp
- Python
- sklearn
- 통계
- 데이터 전처리
- IRIS
- 이것이 코딩테스트다
- ML
- 머신러닝
- 딥러닝
- 코딩테스트
- pandas
- SQLD
- r
- 시각화
- SQL
- Today
- Total
목록전체 글 (142)
함께하는 데이터 분석
 [회귀분석] Simple linear regression 검정
[회귀분석] Simple linear regression 검정
오늘은 simple linear regression에서 검정(test)을 공부해보겠습니다. 귀무가설 대립가설 세우기 우리는 simple linear regression에서 β_0인 intercept 부분보다 β_1인 기울기 부분에 관심이 있습니다. 그래서 귀무가설에 β_1 = 0을 놓고 우리가 궁금해하는 대립가설에 β_1 =/ 0으로 설정했습니다. 일반적인 가설검정이라고 볼 수 있죠. 그런데 저번 포스트에서 M_0 모델과 M_1 모델을 살펴본 것이 기억나세요? 모델의 관점에서 M_0 모델이 옳은가, M_1 모델이 옳은가로 가설검정을 세우면 위의 기울기의 관점과 동치가 됩니다. M_0 모델은 x_i인 설명변수가 없는 모델이지만 M_1 모델에서 β_1이 0이 되면 x_i가 의미가 없어지기 때문이죠. 그렇다면..
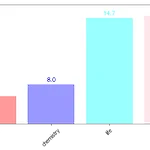 [Python] Matplotlib 막대그래프 그리기
[Python] Matplotlib 막대그래프 그리기
오늘은 matplotlib을 이용하여 막대그래프를 그려보겠습니다. 저번 시간에 활용했던 수능 과학탐구 응시자 수에서 가장 최근인 2022년 데이터를 활용하겠습니다. 라이브러리 불러오기 import matplotlib.pyplot as plt plt.rc('font', family = 'AppleGothic') # mac # plt.rc('font', family = 'Malgun Gothic') # window plt.rc('font', size = 12) plt.rc('axes', unicode_minus = False) # -표시 오류 잡아줌 수능 과학탐구 응시자 수 리스트 science = ['physics', 'chemistry', 'life', 'earth'] people = [6.8, 8.0,..
 [회귀분석] SSE와 결정계수 R^2
[회귀분석] SSE와 결정계수 R^2
오늘은 SSE와 결정계수(R^2)에 대해 알아보겠습니다. 저번 시간에 SSE에 대해서 알아봤는데 오늘은 2가지 model에 대해 SSE를 알아보겠습니다. M_0 model의 SSE m_0 model은 독립변수인 x_i가 없는 모델입니다. 빨간색 x표시가 observation인데 Y축 위에 있는 것을 볼 수 있죠. 이때 SSE는 위와 같습니다. SSE는 Sum of Square Estimation의 약자이죠. M_1 model의 SSE M_1 model이 우리가 알고 있는 simple linear regression입니다. M_1의 SSE가 우리가 말하는 일반적인 SSE입니다. M_0과 M_1 model의 SSE비교 observarion에서 회귀선으로 내린 선분의 제곱한 값이 SSE인 것은 다들 알고 계실..
 [Python] 규제 회귀 모델
[Python] 규제 회귀 모델
이어서 Python으로 규제 회귀 모델인 라쏘, 릿지, 엘라스틱넷 regression을 알아보겠습니다. 모듈 및 데이터 불러오기 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNet, LassoCV, RidgeCV, ElasticNetCV from sklearn.preprocessing import StandardScaler from sklearn import met..
 규제 회귀 모델
규제 회귀 모델
오늘은 규제 회귀 모델인 Lasso, Ridge, ElasticNet Regression에 대해 알아보겠습니다. 규제 회귀 모델 사용 배경 규제 회귀 모델 이전에 우리들이 많이들 알고 있는 선형 회귀 모형이 있습니다. 회귀모델의 목적은 크게 2가지입니다. 독립변수들의 연관성과 미래 데이터의 예측이죠. 그래서 예측력을 높이기 위해 학습 데이터에 지나치게 맞추게 되고 과적합(overfitting)의 문제가 발생하게 됩니다. 그래서 overfitting의 문제를 해결하기 위해 overfitting 된 파라미터에 페널티를 부여하는 규제 회귀모델이 등장합니다. Lasso Regression L1-norm 페널티항으로 회귀모델에 페널티를 부과하여 모델의 설명력에 기여하지 못하는 독립변수의 회귀계수 크기를 0에 가깝..
 [데이터 마이닝] Cluster Analysis
[데이터 마이닝] Cluster Analysis
오늘은 비지도학습인 Cluster Analysis(군집분석)을 공부해보겠습니다. Clustering 이란? - 데이터에서 속성(input variables)에 따라 데이터들(observations) 간의 유사성을 측정하여 군집(cluster)을 찾는 것 - 군집을 찾을 때는 같은 군집 내의 데이터들은 가능한 동질성을 갖게 하고, 군집 간 데이터들은 가능한 이질성을 갖게 해야 함 Cluster Analysis의 활용 고객의 세분화 고객의 맞춤 관리 구매패턴에 따른 신상품 판촉 교차판매 유사성 거리 측도 Euclidean Distance : 직선 거리 Manhattan Distance : ㄱ자 거리 Mahalanobis Distance : 표준화와 상관성을 동시에 고려한 거리 이때 S는 표본 공분산 행렬 S..
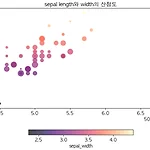 [Python] Matplotlib 산점도 그래프 그리기
[Python] Matplotlib 산점도 그래프 그리기
오늘은 Maplotlib을 이용하여 산점도 그래프를 그려보겠습니다. 라이브러리 불러오기 import numpy as np import pandas as pd import matplotlib.pyplot as plt plt.rc('font', family = 'AppleGothic') # mac # plt.rc('font', family = 'Malgun Gothic') # window plt.rc('font', size = 12) plt.rc('axes', unicode_minus = False) # -표시 오류 잡아줌 데이터 불러오기 import seaborn as sns iris = sns.load_dataset('iris') 이번에는 seaborn에 내장되어있는 데이터인 iris데이터를 이용하여 산..
 [Python] Matplotlib 그래프에 텍스트 삽입
[Python] Matplotlib 그래프에 텍스트 삽입
안녕하세요! 오늘은 지금까지 그렸던 한 개의 선 그래프나 여러 개의 선 그래프에 텍스트를 삽입하는 것을 알아보겠습니다. 그래프는 전 포스트에 작성한 코드를 그대로 가져올 것입니다. 각각의 그래프에 y값을 보기 쉽게 넣어주도록 할게요. 한 개의 선 그래프에 텍스트 삽입 import numpy as np import pandas as pd import matplotlib.pyplot as plt import random import matplotlib.pyplot as plt plt.rc('font', family = 'AppleGothic') # mac # plt.rc('font', family = 'Malgun Gothic') # window plt.rc('font', size = 12) plt.rc('..
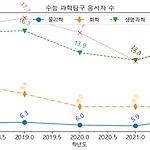
 [Python] Matplotlib 평면내 여러 개의 선 그래프 그리기
[Python] Matplotlib 평면내 여러 개의 선 그래프 그리기
오늘은 한 평면 내에 여러 개의 선 그래프를 그리는 것을 공부하겠습니다. 예제로 2018학년도부터 2022학년도 까지 총 5개년 수능 과학탐구 과목별 응시자 수를 그래프로 그려보겠습니다. 라이브러리 불러오기 import matplotlib.pyplot as plt 한글 오류 기본 설정 plt.rc('font', family = 'AppleGothic') # mac # plt.rc('font', family = 'Malgun Gothic') # window plt.rc('font', size = 12) plt.rc('axes', unicode_minus = False) # -표시 오류 잡아줌 전 포스트에 적어놨던 한글 오류 설정입니다. 수능 과탐 데이터 리스트 # 년도 year = [2018, 2019, ..
 [데이터 마이닝] 의사결정나무(Decision Trees)
[데이터 마이닝] 의사결정나무(Decision Trees)
오늘은 데이터 마이닝의 분석방법 중 하나인 의사결정나무를 알아보겠습니다. 의사결정나무의 정의 - 과거에 수집된 데이터들을 분석하여 이들 사이에 존재하는 패턴 즉, 범주별 특성을 속성의 조합으로 나타내는 분류 모형 의사결정나무의 목적 - 새로운 데이터에 대해 분류(Classification)하거나 해당 범주의 값을 예측하는 것 변수 유형에 따른 분류 범주형 : 분류나무(Classification Tree) 연속형 : 회귀나무(Regression Tree) 의사결정나무 구성요소 노드(Node) 가지(Branch) 깊이(Depth) : 깊어질수록 복잡도 상승 제일 위의 신용도에서 가지가 쳐서 나오므로 root node라고 하고 마지막 노드를 terminal node라고 합니다. 여기서 신용도와 나이, 성별을 ..