| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터분석준전문가
- IRIS
- 시각화
- 회귀분석
- 딥러닝
- SQL
- r
- 머신러닝
- 이코테
- pytorch
- Google ML Bootcamp
- 파이썬
- 코딩테스트
- Deep Learning Specialization
- ADsP
- 데이터분석
- 이것이 코딩테스트다
- Python
- 통계
- sklearn
- matplotlib
- SQLD
- ML
- scikit learn
- 데이터 전처리
- pandas
- 태블로
- 자격증
- 데이터 분석
- tableau
- Today
- Total
함께하는 데이터 분석
[ML] 교차검증과 하이퍼파라미터 튜닝 본문
교차검증과 하이퍼파라미터 튜닝은 머신러닝 모델의 성능을 높이기 위해 사용하는 기법
교차검증
학습과 검증을 위해 train set, validation set, test set으로 데이터를 나눔
하지만 이러한 방법은 overfitting에 취약할 수 있고 데이터의 개수가 적을 때 어려움이 있음
그리고 고정된 train set와 test set으로 평가를 하다 보면 test set에서만 최적의 성능을 발휘하도록
편향될 수 있기에 이 문제를 해결하기 위해 나온 것이 교차검증

raw 데이터가 충분하지 않을 때 사용하는 방법이 k-fold cross validation
가장 보편적으로 사용되는 교차검증 기법으로 train set를 k개로 분할하여
1개의 validation fold를 나머지 k-1개의 training fold를 만들어 학습과 검증 평가를 반복적으로 수행
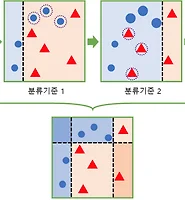
위의 사진을 참고하면 파란색으로 validation set이 설정되면 나머지 회색이 training set이 됨
하이퍼파라미터 튜닝
머신러닝 모델을 구성하는 하이퍼 파라미터를 조정해 알고리즘의 성능을 개선하는 것이 하이퍼파라미터 튜닝
그중 가장 보편적으로 사용되는 Grid Search를 알아볼 것
Grid Search는 하이퍼 파라미터의 집합을 만들어 이를 순차적으로 적용하여 최적화를 수행
지정해 준 여러 하이퍼 파라미터를 순차적으로 조합하여 최고의 성능을 나타내는 파라미터 조합을 찾아줌
이때 단점은 학습하고자 하는 파라미터 수에 따라 학습이 많이 늘어나서 시간이 오래 걸리는 것
교차검증 & 하이퍼 파라미터 튜닝 실습
import numpy as np
import pandas as pd
import sklearn
import warnings
warnings.filterwarnings('ignore')from sklearn.datasets import load_iris
iris = load_iris()
X = iris['data']
y = iris['target']from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=1234)train set, test set 8:2로 분리하고 시드넘버를 1234로 지정
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(max_depth=1, random_state=1234)
model.fit(X_train, y_train)
pred = model.predict(X_test)iris 데이터 자체가 아주 예쁜 데이터이므로 accuracy의 차이를 보이기 위해 max_depth를 1로 설정
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
print('-------------- RandomForest --------------')
print('RandomForest Accuracy : ', round(accuracy_score(y_test, pred) * 100, 2))
kfold = KFold(n_splits=5, random_state=1234, shuffle=True)
cross_result = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
print('RandomForest Cross Validation Accuracy : ', round(cross_result.mean() * 100, 2))
>>> -------------- RandomForest --------------
RandomForest Accuracy : 60.0
RandomForest Cross Validation Accuracy : 71.675-fold cross validation을 한 후 성능이 향상되는 것을 볼 수 있음
from sklearn.model_selection import GridSearchCV
model = RandomForestClassifier(max_depth=1, random_state=1234)
param_grid = {'n_estimators' : range(100, 1000, 100)}
model_rf = GridSearchCV(model, param_grid=param_grid, cv=5, scoring='accuracy')
model_rf.fit(X_train, y_train)
print('RandomForest Hyperparameter Tuning Accuracy : ', round(model_rf.best_score_ * 100, 2))
print('RandomForest Hyperparameter Tuning Parameter : ', model_rf.best_params_)
>>> RandomForest Hyperparameter Tuning Accuracy : 80.0
RandomForest Hyperparameter Tuning Parameter : {'n_estimators': 100}Decision Tree의 앙상블 모형이 Random Forest인데 DT 몇 개를 앙상블 할 것인지를 결정하는
n_estimators의 개수를 range(100, 1000, 100)을 통해 100, 200... 900까지를 돌려본 결과
100개의 DT를 앙상블 했을 때의 RF의 accuracy가 제일 높게 나온 것을 확인할 수 있음
'데이터분석 공부 > ML | DL' 카테고리의 다른 글
| [ML] 분류 모델 성능 평가 지표 (0) | 2023.01.17 |
|---|---|
| [ML] Gradient Boosting Machine (0) | 2023.01.15 |
| [Pytorch] 순환 신경망 모델 학습 (2) | 2022.09.20 |
| [RNN] 순환 신경망 (2) | 2022.09.20 |
| [Pytorch] 인공 신경망 모델 학습 (0) | 2022.09.12 |