
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 데이터분석준전문가
- pandas
- 이것이 코딩테스트다
- r
- SQLD
- IRIS
- 머신러닝
- 자격증
- 통계
- 시각화
- Python
- 회귀분석
- sklearn
- 이코테
- Deep Learning Specialization
- Google ML Bootcamp
- 파이썬
- 코딩테스트
- tableau
- 데이터 전처리
- ML
- 태블로
- 데이터분석
- pytorch
- SQL
- ADsP
- scikit learn
- 딥러닝
- 데이터 분석
- matplotlib
Archives
- Today
- Total
함께하는 데이터 분석
[데이터 마이닝] Cluster Analysis 본문
오늘은 비지도학습인
Cluster Analysis(군집분석)을 공부해보겠습니다.
Clustering 이란?
- 데이터에서 속성(input variables)에 따라 데이터들(observations) 간의 유사성을 측정하여 군집(cluster)을 찾는 것
- 군집을 찾을 때는 같은 군집 내의 데이터들은 가능한 동질성을 갖게 하고, 군집 간 데이터들은 가능한 이질성을 갖게 해야 함

Cluster Analysis의 활용
- 고객의 세분화
- 고객의 맞춤 관리
- 구매패턴에 따른 신상품 판촉
- 교차판매
유사성 거리 측도
- Euclidean Distance : 직선 거리

- Manhattan Distance : ㄱ자 거리
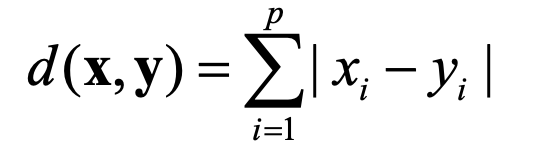
- Mahalanobis Distance : 표준화와 상관성을 동시에 고려한 거리
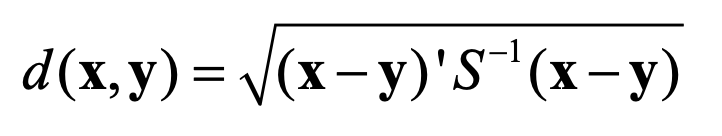
이때 S는 표본 공분산 행렬
- Statistical Distance
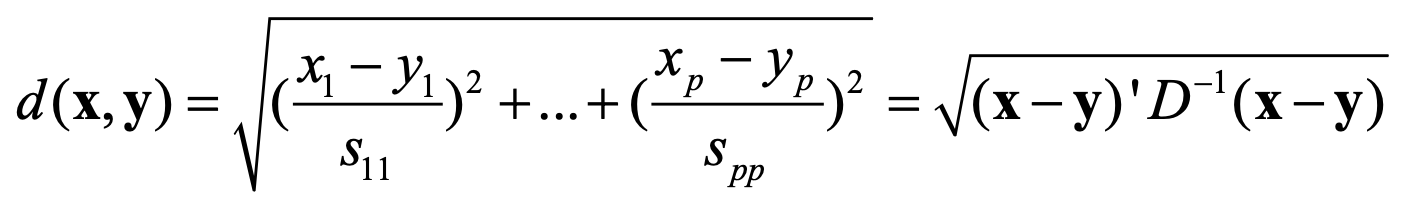
이때 D는 표본 분산 행렬

Cluster Analysis 기법
- 계층적 군집분석(Hierarchical Clustering) : 가까운 관측값들끼리 병합하고 먼 관측값들을 분할하는 방법
- 비계층적 군집분석(Partitional Clustering) : 관측값들을 몇 개의 군집으로 나누기 위한 방법. 대표적으로 K-means clustering
Hierarchical Clustering Algorithms
- 각 개체를 하나의 군집으로 전체 n개의 군집 형성
- 각 군집 간의 거리를 계산하여 가장 가까운 두 개의 군집을 합침
- 전 개체가 하나의 군집이 될 때까지 군집을 계속 합침
군집 간의 거리
- 최단 연결법 : 두 군집에서 가장 가까운 데이터 간의 거리
- 최장 연결법 : 두 군집 사이에서 가장 멀리 떨어진 데이터 간의 거리
- 중심 연결법 : 두 군집의 중심 간의 거리
- 평균 연결법 : 평균 거리
- 와드 연결법 : 군집 내 편차들의 제곱 합의 최소 거리(SSE). 정보 손실을 최소화
Hierarchical Clustering의 장점
- 군집의 수를 미리 정할 필요가 없다
- 유사성이 가까운 순서대로 군집화하여 간단하고 명확
- Dendrogram을 통해 군집화 과정과 결과물을 시각화하여 보여줌
Hierarchical Clustering의 단점
- 데이터 집합이 매우 클 경우 계산속도가 느림
- 안정성이 낮음. 데이터를 재 정렬하거나 제외시키면 전혀 다른 결과 발생
- 한번 군집에 할당되면 다른 군집에 포함이 안됨
- 이상 값에 민감함(중심연결법이 이상값에 덜 민감)
K-means Clustering Algorithms
- 군집수 k를 설정
- 초기 k개 군집의 중심을 선택(변동 가능)
- 데이터를 그 중심과 가장 가까운 거리에 있는 군집에 할당
- 위의 과정을 기존의 중심과 새로운 중심의 차이가 없을 때까지 반복
K-means Clustering의 장점
- 사용이 쉽고 간편
- 분류·예측을 위한 선행작업이나, 특이값, 결측값 처리 작업 등에도 사용 가능
K-means Clustering의 단점
- 속성들의 형태가 다르거나 같은 속성이라도 값의 범위가 다양할 경우 측정기준 설정이 어려움
- 군집수 k를 설정하고 들어가는데, 만약 데이터의 군집의 수가 k보다 작거나 크다면 결과가 좋지 않음
'통계학과 수업 기록 > 데이터 마이닝' 카테고리의 다른 글
| [데이터 마이닝] 연관성 분석(Association Analysis) (0) | 2022.04.06 |
|---|---|
| [데이터 마이닝] 의사결정나무(Decision Trees) (0) | 2022.03.29 |
| [데이터 마이닝] 로지스틱 단순회귀모형 (0) | 2022.03.24 |
| [데이터 마이닝] 분석기법 분류 (0) | 2022.03.15 |
| [데이터 마이닝] 데이터분석과 방법론 개요 (0) | 2022.03.14 |
'통계학과 수업 기록/데이터 마이닝' Related Articles
more



