
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 이것이 코딩테스트다
- matplotlib
- tableau
- Deep Learning Specialization
- ADsP
- 파이썬
- 시각화
- 이코테
- Google ML Bootcamp
- 코딩테스트
- ML
- sklearn
- pandas
- 머신러닝
- Python
- 회귀분석
- 딥러닝
- 데이터분석준전문가
- 자격증
- IRIS
- SQL
- r
- scikit learn
- 데이터분석
- 데이터 전처리
- 데이터 분석
- 통계
- pytorch
- SQLD
- 태블로
- Today
- Total
목록pca (2)
함께하는 데이터 분석
 [Scikit Learn] PCA
[Scikit Learn] PCA
주성분 분석(Principal Component Analysis) 차원을 축소하는 알고리즘 중 가장 인기 있는 알고리즘 사이킷런 import numpy as np np.random.seed(4) m = 60 w1, w2 = 0.1, 0.3 noise = 0.1 angles = np.random.rand(m) * 3 * np.pi / 2 - 0.5 X = np.empty((m, 3)) X[:, 0] = np.cos(angles) + np.sin(angles)/2 + noise * np.random.randn(m) / 2 X[:, 1] = np.sin(angles) * 0.7 + noise * np.random.randn(m) / 2 X[:, 2] = X[:, 0] * w1 + X[:, 1] * w2 + n..
 [EDA] PCA with R
[EDA] PCA with R
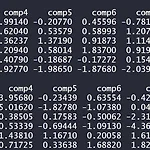
오늘은 Principal Component Analysis 일명 PCA에 대해 간단한 예제를 R을 통해 알아보는 시간을 갖겠습니다! 그러기에 앞서 필요한 파일을 첨부하겠습니다. 위 데이터는 주식에 관한 10개 회사의 값입니다. 그럼 시작해볼까요? rm(list=ls()) #할당변수 모두 제거 load("stockreturns.RData") #데이터 불러오기 ls() #변수 확인 >>> [1] "stocks" head(stocks) tail(stocks) str(stocks) #구조 파악 >>> 'data.frame':100 obs. of 10 variables: $ comp1 : num 0.44781 0.98811 0.87456 0.7144 0.00535 ... $ comp2 : num 0.0673 1...