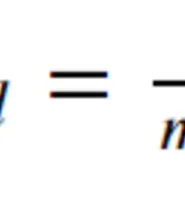| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터 분석
- ADsP
- IRIS
- 자격증
- 이것이 코딩테스트다
- 코딩테스트
- 이코테
- Python
- 파이썬
- SQLD
- Google ML Bootcamp
- 태블로
- 통계
- 머신러닝
- sklearn
- matplotlib
- 시각화
- Deep Learning Specialization
- tableau
- SQL
- 데이터분석
- 데이터분석준전문가
- 데이터 전처리
- pytorch
- r
- 회귀분석
- ML
- pandas
- 딥러닝
- scikit learn
- Today
- Total
함께하는 데이터 분석
[Scikit Learn] Min-Max Scaling 본문
저번 시간에 본 Standard Scaling에 이어서
오늘은 Min-Max Scaling을 공부해보겠습니다.
스케일링을 하는 이유는 앞선 포스팅인
2022.05.10 - [데이터분석 공부/ML | DL] - [Scikit Learn] Standard Scaling
[Scikit Learn] Standard Scaling
안녕하세요. 오늘은 Numerical feature를 Scaling을 해보겠습니다. Scaling의 여러 가지 방법 중 Standard Scaling을 알아보겠습니다. 우선 Scaling을 하는 이유를 말씀드리겠습니다. 예를 들어 머신러닝을 진행
tnqkrdmssjan.tistory.com
이 포스팅을 참고해주세요!
이제 본격적으로 Min-Max Scaling을 알아보겠습니다.
Min-Max Scaling

Min-Max Scaling은 데이터의 값에서 데이터의 최솟값을 뺀 것을
최댓값에서 최솟값을 뺀 값으로 나눠줍니다.
데이터의 값들이 모두 같지 않으면 분모는 항상 양수일 것입니다.
분자를 살펴보면 데이터의 값이 최댓값이면 분모 분자가 같아져 1이 됩니다.
데이터의 값이 최솟값이면 분자가 0이어서 0이 되죠.
따라서 Min-Max Scaling은 0에서 1 사이로
데이터를 스케일링해주는 특징이 있습니다.
Min-Max Scaling은 Standard Scaling과 같이 이상치에 민감하다는 특징이 있지만
Standard Scaling과 함께 가장 자주 쓰이는 스케일링이기도 합니다.
이제 Python에서 Min-Max Scaling을 진행해보겠습니다.
라이브러리 불러오기
import numpy as np
import pandas as pd
import seaborn as sns
import sklearn저번 포스팅에서와 똑같이 라이브러리를 불러왔습니다.
데이터도 마찬가지로 mpg 데이터를 사용하겠습니다.
데이터 불러오기 및 정제하기
mpg = sns.load_dataset('mpg')
mpg.head()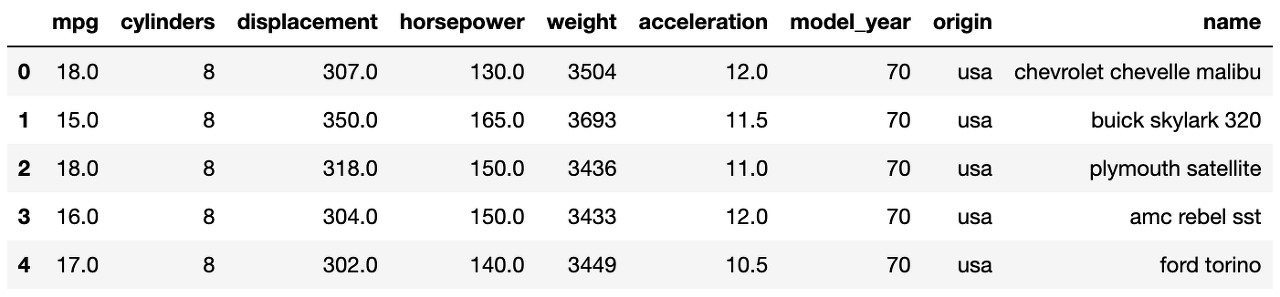
마찬가지로 스케일링을 하기 위해 수치형 변수와 범주형 변수를 분리시키겠습니다.
numerical_mpg = mpg.dtypes[mpg.dtypes != "object"].index.tolist()
numerical_mpg
>>> ['mpg',
'cylinders',
'displacement',
'horsepower',
'weight',
'acceleration',
'model_year']
mpg = mpg[numerical_mpg]
mpg.head()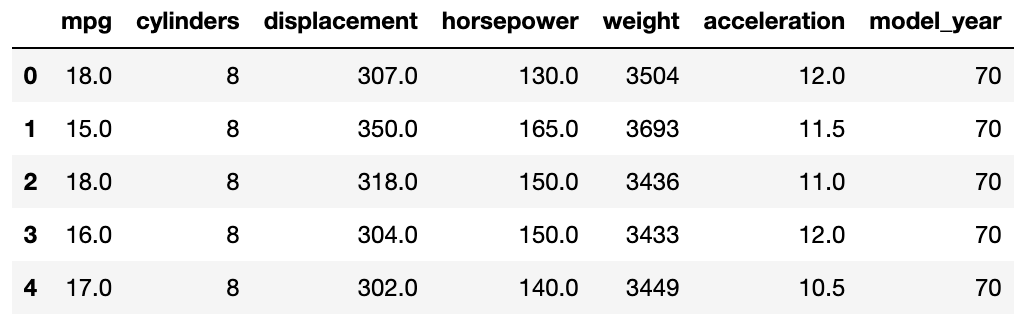
이제 수치형 변수만 남은 것을 확인할 수 있습니다.
이제 요약 통계량을 살펴볼게요.
mpg.describe()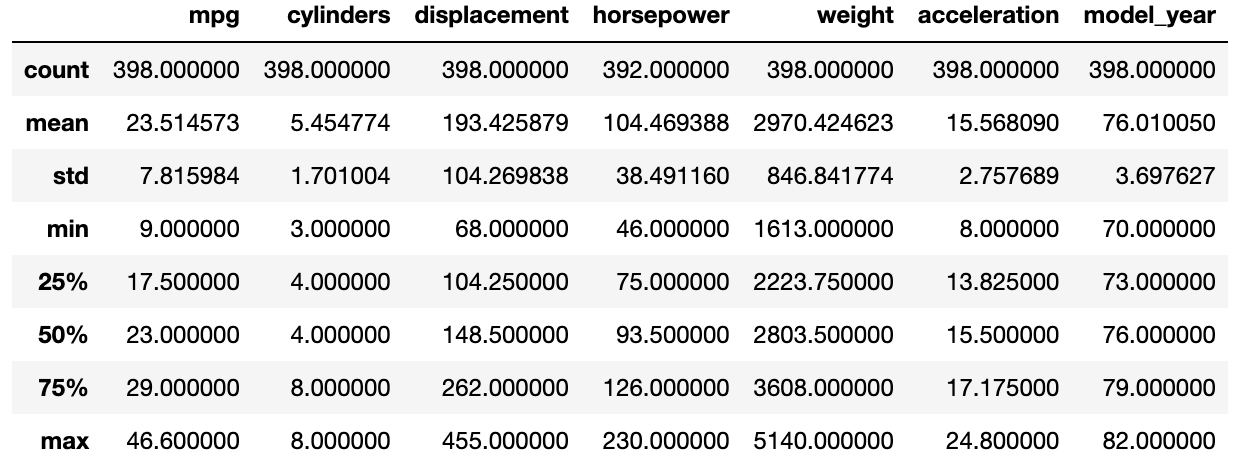
이제 본격적으로 Min-Max Scaling을 시작해볼게요.
수식을 통한 Min-Max Scaling
fmmpg = (mpg - np.min(mpg)) / (np.max(mpg) - np.min(mpg))formula mpg의 약자인 fmmpg에 위의 수식을 넣어줬습니다.
numpy를 이용하여 데이터 값을 최솟값으로 뺐고
그것을 최댓값에서 최솟값을 뺀 것으로 나눠줬습니다.
fmmpg.head()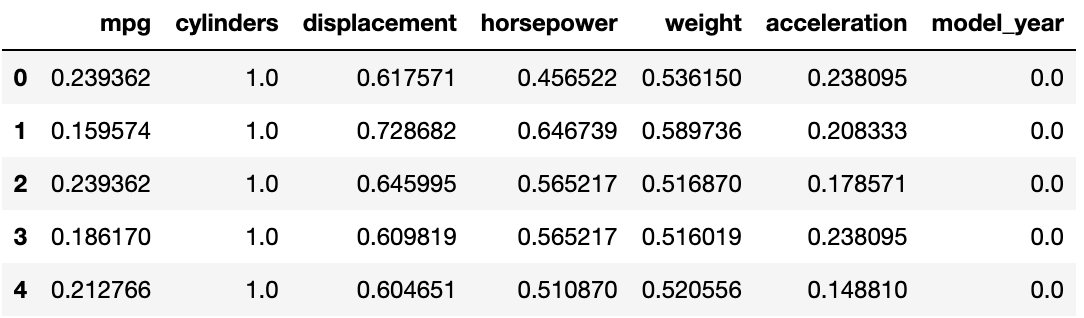
값이 0과 1 사이에 존재하고 벗어나는 값이 존재하지 않습니다.
요약 통계량을 살펴볼게요.
fmmpg.describe()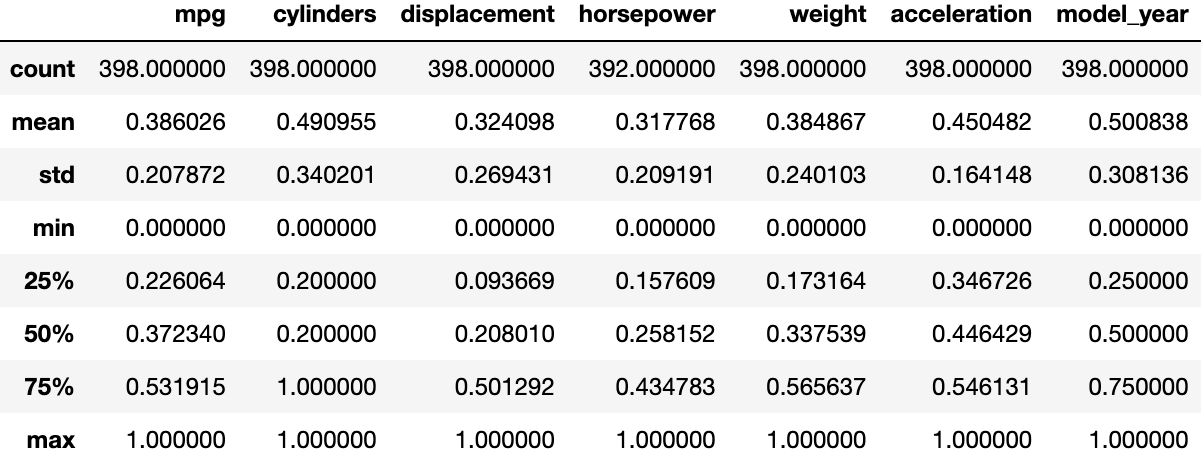
min과 max를 살펴보면 각각 0과 1인 것을 보아
수식을 통한 Min-Max Scaling이 잘 된 것을 확인할 수 있습니다.
이제 Scikit Learn을 통해 Min-Max Scaling을 진행해볼게요.
Scikit Learn을 활용한 Min-Max Scaling
from sklearn.preprocessing import MinMaxScaler
mMscaler = MinMaxScaler()앞서 불러온 sklearn의 preprocessing 패키지에서
MinMaxScaler를 불러왔습니다.
그리고 mMscaler에 할당해줬습니다.
skmpg = mMscaler.fit_transform(mpg)이후 sklearn mpg의 약자인 skmpg에 Min-Max Scaling을 할 mpg데이터를 할당했습니다.
이제 Min-Max Scaling이 제대로 됐는지 확인해볼게요.
skmpg.describe() # sklearn 사용하면 numpy.ndarray
마찬가지로 sklearn을 사용한 skmpg 데이터가 데이터 프레임 형식이 아닙니다.
따라서 pandas를 활용하여 데이터 프레임 형식으로 바꿔주겠습니다.
skmpg = pd.DataFrame(skmpg, columns = mpg.columns)이제 head와 describe를 통해
제대로 스케일링이 됐는지 살펴볼게요.
skmpg.head()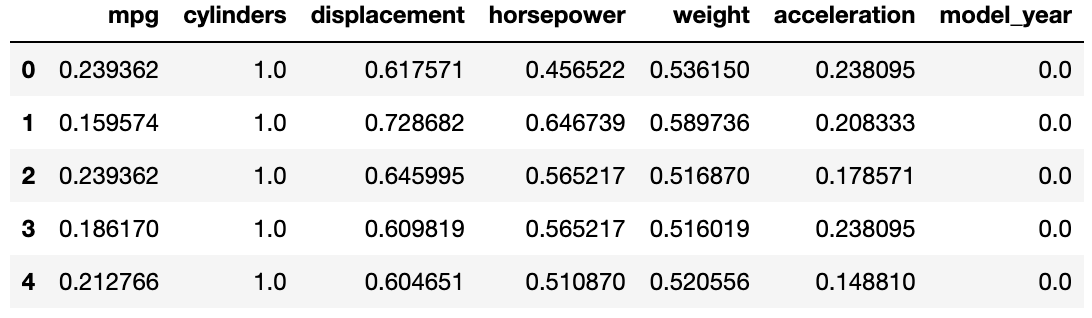
앞서 수식을 통해 Min-Max Scaling을 한 결과와 똑같이 스케일링이 된 것을 볼 수 있습니다.
skmpg.describe()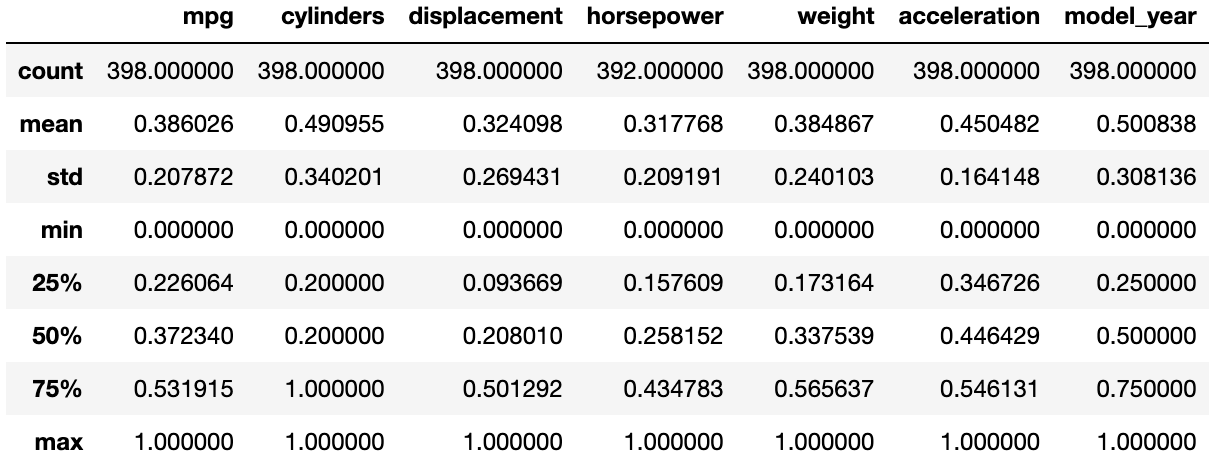
요약 통계량도 마찬가지네요.
다음에는 Min-Max Scaling과 약간 유사한 면이 있는
MaxAbs Scaling을 살펴보겠습니다!
'데이터분석 공부 > ML | DL' 카테고리의 다른 글
| [Scikit Learn] One-Hot Encoding (0) | 2022.05.13 |
|---|---|
| [Scikit Learn] Label Encoding (0) | 2022.05.13 |
| [Scikit Learn] Robust Scaling (0) | 2022.05.10 |
| [Scikit Learn] MaxAbs Scaling (0) | 2022.05.10 |
| [Scikit Learn] Standard Scaling (0) | 2022.05.10 |