
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 데이터분석준전문가
- SQLD
- Python
- 코딩테스트
- 파이썬
- 데이터 전처리
- ML
- 시각화
- pandas
- IRIS
- 자격증
- 이코테
- SQL
- 딥러닝
- 머신러닝
- scikit learn
- 데이터 분석
- Deep Learning Specialization
- Google ML Bootcamp
- ADsP
- 회귀분석
- matplotlib
- r
- 통계
- 태블로
- sklearn
- pytorch
- tableau
- 데이터분석
- 이것이 코딩테스트다
- Today
- Total
함께하는 데이터 분석
[Scikit Learn] Robust Scaling 본문
오늘은 마지막 스케일링인
Robust Scaling에 대해 알아보겠습니다.
Robust Scaling

Robust Scaling은 데이터 값에서 데이터의 중위수를 뺀 것을
IQR인 Q3 - Q1으로 나눈 것입니다.
통계를 배우다 보면 중위수가 이상치에 강하다는 특징을 배울 것입니다.
이 Robust Scaling 역시 이상치의 영향을 최소화하는 스케일링입니다.
Standard Scaling에 비해 넓은 범위로 스케일링되는 특징이 있습니다.
이제 Python을 통해 Robust Scaling을 진행하겠습니다.
라이브러리 불러오기
import numpy as np
import pandas as pd
import seaborn as sns
import sklearn
데이터 불러오기 및 정제하기
mpg = sns.load_dataset('mpg')
mpg.head()
seaborn 라이브러리의 mpg데이터를 불러왔습니다.
스케일링을 하기 위해 mpg데이터를
수치형 변수로만 이루어진 데이터로 만들어주겠습니다.
numerical_mpg = mpg.dtypes[mpg.dtypes != "object"].index.tolist()
numerical_mpg
>>> ['mpg',
'cylinders',
'displacement',
'horsepower',
'weight',
'acceleration',
'model_year']
mpg = mpg[numerical_mpg]
mpg.head()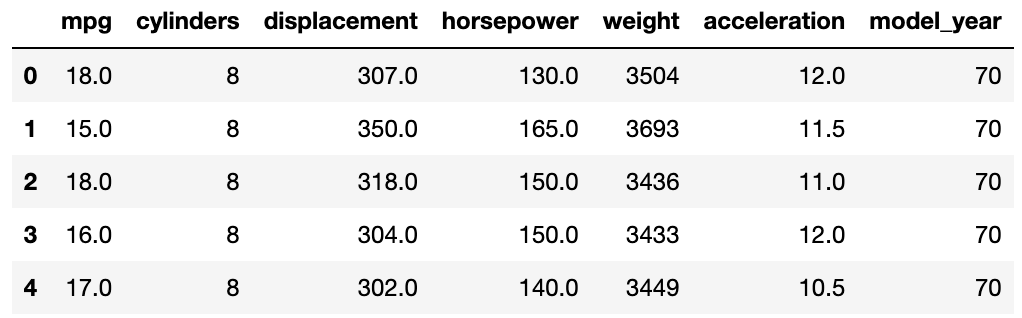
mpg.describe()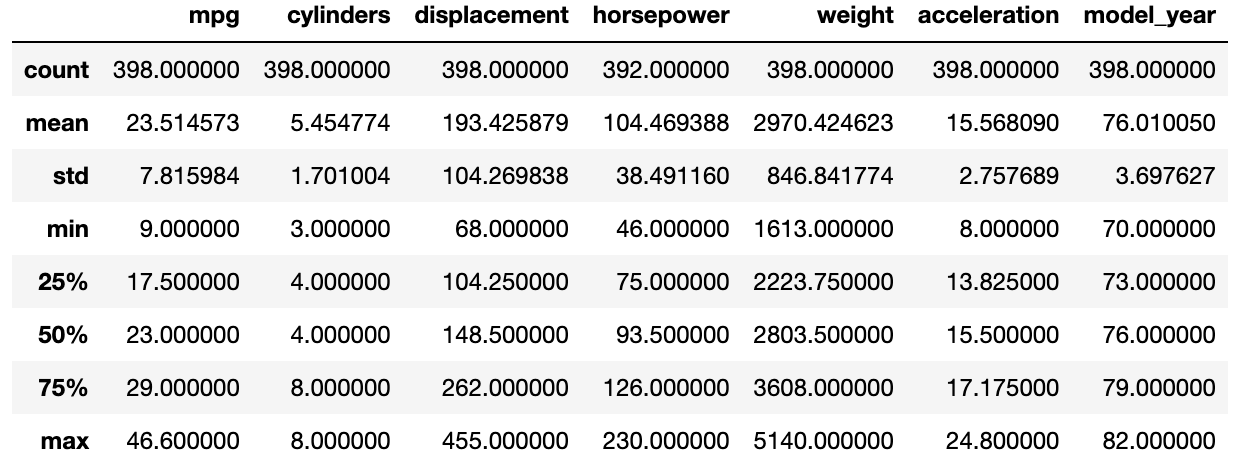
이제 Robust Scaling을 시작해볼게요!
Scikit Learn을 활용한 Robust Scaling
from sklearn.preprocessing import RobustScaler
rbscaler = RobustScaler()sklearn의 preprocessing 패키지에 RobustScaler가 있습니다.
그리고 rbscaler로 RobustScaler를 할당시켰습니다.
skmpg = rbscaler.fit_transform(mpg)이후 sklearn mpg의 약자인 skmpg에 Robust Scaling을 할 mpg데이터를 할당했습니다.
이제 Robust Scaling이 제대로 진행됐는지 확인하겠습니다.
skmpg.describe() # sklearn 사용하면 numpy.ndarray
이제는 자동으로 pandas를 활용하여 데이터 프레임 형식으로 변경해주겠습니다.
skmpg = pd.DataFrame(skmpg, columns = mpg.columns)이제 head와 describe를 통해
스케일링이 제대로 진행됐는지 살펴볼게요.
skmpg.head()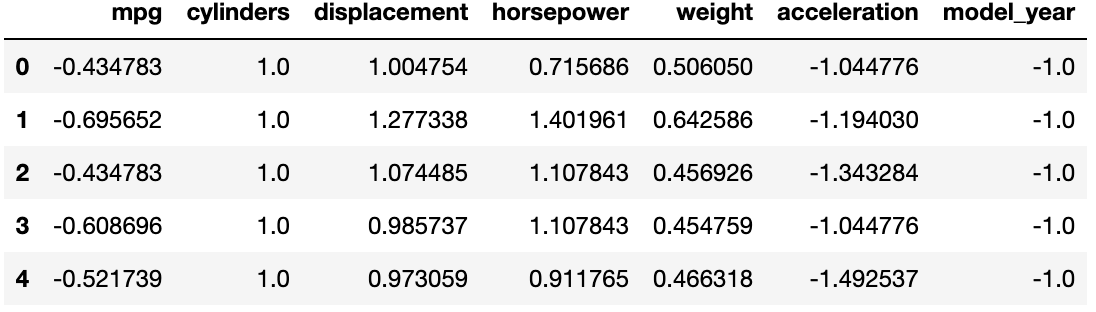
데이터가 스케일링 된 것을 확인할 수 있습니다.
skmpg.describe()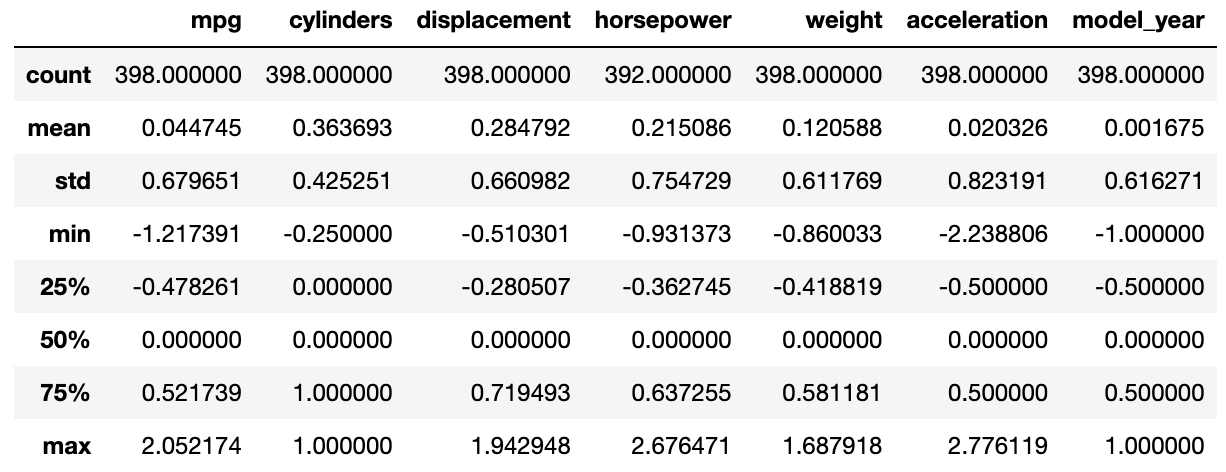
여기서 Robust Scaling을 마치겠습니다.
추가로 스케일링은 데이터의 결측치나 이상치를 처리한 후에 진행하는 것이 바람직합니다!
'데이터분석 공부 > ML | DL' 카테고리의 다른 글
| [Scikit Learn] One-Hot Encoding (0) | 2022.05.13 |
|---|---|
| [Scikit Learn] Label Encoding (0) | 2022.05.13 |
| [Scikit Learn] MaxAbs Scaling (0) | 2022.05.10 |
| [Scikit Learn] Min-Max Scaling (1) | 2022.05.10 |
| [Scikit Learn] Standard Scaling (0) | 2022.05.10 |



