
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 파이썬
- 데이터 전처리
- scikit learn
- IRIS
- 데이터분석준전문가
- 딥러닝
- 자격증
- pytorch
- 머신러닝
- 이코테
- r
- 이것이 코딩테스트다
- 통계
- SQLD
- sklearn
- 회귀분석
- ML
- matplotlib
- Python
- ADsP
- 데이터분석
- 데이터 분석
- 코딩테스트
- Google ML Bootcamp
- 시각화
- tableau
- 태블로
- Deep Learning Specialization
- pandas
- SQL
- Today
- Total
목록학회 세션 (23)
함께하는 데이터 분석
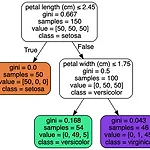 [Find-A][Scikit Learn] Decision Tree
[Find-A][Scikit Learn] Decision Tree
의사결정 나무(Decision Tree) 분류와 회귀 작업, 다중출력 작업도 가능한 다재다능한 머신러닝 알고리즘 최근에 자주 사용되는 강력한 머신러닝 알고리즘 중 하나인 랜덤 포레스트의 기본 구성 요소 1. 의사결정 나무 학습과 시각화 from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier iris = load_iris() X = iris['data'][:, (2, 3)] y = iris['target'] 사이킷런의 iris 데이터를 불러오고 X에 PetalLength, PetalWidth y에 꽃의 품종인 Setona, Versicolor, Virginica를 할당 tree_clf = DecisionTr..
 [Find-A] [Scikit Learn] 소프트맥스 회귀
[Find-A] [Scikit Learn] 소프트맥스 회귀
이번에는 소프트맥스 회귀를 진짜 맛만 보겠습니다. 정말 간단하게 저번에 봤던 iris 데이터를 가지고 코드만 돌려보는 식으로 진행할게요! 이전의 데이터 설명이나 로지스틱 회귀를 파이썬으로 돌린 포스팅은 2022.08.19 - [학회 세션/파인드 알파] - [Find - A] [Python] 로지스틱 회귀 [Find - A] [Python] 로지스틱 회귀 안녕하세요! 오늘은 로지스틱 회귀모형을 Python으로 돌려보겠습니다. 다른 포스팅에도 개념은 설명되어 있어 간단하게 말하고 넘어갈게요. 로지스틱 회귀는 이진 분류기로 샘플이 특정 클래스 tnqkrdmssjan.tistory.com 여기를 확인하시면 됩니다. 시작할게요! 소프트맥스 회귀 로지스틱 회귀 모델은 여러 개의 이진 분류기를 훈련시켜 연결하지 않고..
 [Find-A] [Scikit Learn] 로지스틱 회귀
[Find-A] [Scikit Learn] 로지스틱 회귀
안녕하세요! 오늘은 로지스틱 회귀모형을 Python으로 돌려보겠습니다. 다른 포스팅에도 개념은 설명되어 있어 간단하게 말하고 넘어갈게요. 로지스틱 회귀는 이진 분류기로 샘플이 특정 클래스에 속할 확률을 추정합니다. 추정 확률이 50%가 넘으면 그 샘플이 해당 클래스에 속한다고 예측합니다. 0 이면 음성 클래스, 1이면 양성 클래스로 보통 분류합니다. 이제 Python의 iris데이터를 활용하여 분류해볼게요! 라이브러리 불러오기 import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import sklearn import warnings warnings.filterwarnings('ignore')..
안녕하세요. 오늘은 파인드 알파 학회에서 팀을 짜서 공부한 내용을 정리하는 시간을 가지겠습니다. 한 달에 걸쳐 공부할 책은 Hands-On Machine Learning with Scikit-Learn & TensorFlow 입니다. 이번에는 그중에서도 Chapter 1을 정리하겠습니다. 1. 한눈에 보는 머신러닝 1.1 머신러닝이란? 머신러닝의 공학적인 정의는 "어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다."이다. 예를 들어 스팸 필터라고 한다면 학습하는 데 사용하는 샘플을 training set, 작업 T는 새로운 메일이 스팸인지 구별하는 것, 경험 E는 trainin..
 [Python] 규제 회귀 모델
[Python] 규제 회귀 모델
이어서 Python으로 규제 회귀 모델인 라쏘, 릿지, 엘라스틱넷 regression을 알아보겠습니다. 모듈 및 데이터 불러오기 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNet, LassoCV, RidgeCV, ElasticNetCV from sklearn.preprocessing import StandardScaler from sklearn import met..
 규제 회귀 모델
규제 회귀 모델
오늘은 규제 회귀 모델인 Lasso, Ridge, ElasticNet Regression에 대해 알아보겠습니다. 규제 회귀 모델 사용 배경 규제 회귀 모델 이전에 우리들이 많이들 알고 있는 선형 회귀 모형이 있습니다. 회귀모델의 목적은 크게 2가지입니다. 독립변수들의 연관성과 미래 데이터의 예측이죠. 그래서 예측력을 높이기 위해 학습 데이터에 지나치게 맞추게 되고 과적합(overfitting)의 문제가 발생하게 됩니다. 그래서 overfitting의 문제를 해결하기 위해 overfitting 된 파라미터에 페널티를 부여하는 규제 회귀모델이 등장합니다. Lasso Regression L1-norm 페널티항으로 회귀모델에 페널티를 부과하여 모델의 설명력에 기여하지 못하는 독립변수의 회귀계수 크기를 0에 가깝..
 [R] 로지스틱 회귀 & LDA
[R] 로지스틱 회귀 & LDA
오늘은 R코드를 통해 간단한 예시로 로지스틱 회귀분석과 LDA를 알아보겠습니다. 자료는 R패키지인 ISLR에서 Smarket 데이터를 이용하겠습니다. Smarket 데이터는 2001년부터 2005년까지의 1250일에 걸친 S&P500 주가지수 수익률을 나타낸 데이터입니다. 변수 설명 Year 연도(2001년 ~ 2005년) Lag1 ~Lag5 해당 날짜 1~5일 전의 수익률 Volume 해당 날짜 전날에 거래된 주식 수(단위 : 10억 주) Today 당일의 수익률 Direction 당일 주가 지수 상승 / 하락 여부(UP / DOWN) 데이터 불러오기 library(ISLR) stocks >> [1] "Year" "Lag1" "Lag2" "Lag3" [5] "Lag4" "Lag5" "Volume" "T..
 [Classification] LDA(선형 판별분석)
[Classification] LDA(선형 판별분석)
반응변수가 범주형인 경우 분류(Classification)를 사용하고 분류기(Classifiers)에 여러 가지가 있지만 저번 시간에 간략하게 다룬 로지스틱 회귀분석에 이은 선형 판별분석 LDA에 대해 알아보겠습니다. 간단한 이론정도에 불과하지만 로지스틱 회귀분석을 살펴보려면 2022.03.24 - [통계학과 수업 기록/데이터 마이닝] - [데이터 마이닝] 로지스틱 단순회귀모형 [데이터 마이닝] 로지스틱 단순회귀모형 안녕하세요! 오늘은 로지스틱 단순 회귀모형에 대해 알아보겠습니다. 위의 사진에서 주황색 그래프가 로지스틱 회귀 곡선입니다. 로지스틱 회귀모형은 설명변수인 x는 연속형이든 범주형이든 tnqkrdmssjan.tistory.com 여기로 이동해주시면 감사하겠습니다. 분류를 위한 베이즈 정리 사용 ..
 [Python] IMAGE(2D data) AUGMENTATION
[Python] IMAGE(2D data) AUGMENTATION
안녕하세요! 오늘은 이미지 증강(Image Augmentation)을 python을 통해 구현해보겠습니다. Image Augmentation은 몇 개의 이미지를 활용하여 이미지에 여러 가지 변화를 주어 데이터의 양을 증가시키는 것입니다. 장점은 데이터 다양성 향상과 모델 성능 향상 등이 있습니다. 그렇다면 python에서 살펴볼까요? 라이브러리 불러오기 import numpy as np from matplotlib.pyplot import imshow, subplots, title from PIL import Image from torchvision import transforms import albumentations import random 이미지 불러오고 그리기 img = Image.open('경로..
 [R] 데이터 불균형 해소
[R] 데이터 불균형 해소
오늘은 이어서 데이터 불균형 해소를 간단한 R코드를 통해 알아보겠습니다. 2022.03.20 - [학회 기록/학회 세션] - 데이터 불균형 해소 데이터 불균형 해소 안녕하세요! 오늘은 데이터가 불균형이어서 우리가 모델링을 할 때 유의미한 결과값을 얻을 수 없을 때 어떻게 대처해야하는지를 알아보겠습니다. 예를들면 종양의 악성유무를 살펴보면 100명 tnqkrdmssjan.tistory.com 이전 발행 글은 위를 참고하시면 됩니다. 기본 데이터 # 문과(0) 이과(1) set.seed(0320) y = c(rep(0, 15), rep(1, 50)) y = as.factor(y) math = c(rnorm(15, 50, 15), rnorm(50, 70, 12)) eng = c(rnorm(15, 70, 12)..