
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 데이터 분석
- 코딩테스트
- 회귀분석
- 데이터분석
- scikit learn
- 태블로
- IRIS
- 통계
- ML
- ADsP
- 데이터분석준전문가
- 이코테
- 자격증
- 파이썬
- SQLD
- 데이터 전처리
- 머신러닝
- pandas
- matplotlib
- Deep Learning Specialization
- tableau
- SQL
- 이것이 코딩테스트다
- sklearn
- 딥러닝
- 시각화
- r
- Google ML Bootcamp
- Python
- pytorch
- Today
- Total
목록데이터분석 (20)
함께하는 데이터 분석
의사결정나무 알고리즘 분류 기준 알고리즘 이산형 변수 연속형 변수 CART 지니지수 분산감소량 C5.0 엔트로피지수 CHAID 카이제곱 통계량 p-value ANOVA F-통계량 은닉층 노드가 너무 많으면 과적합 문제 은닉층 노드가 너무 적으면 의사결정 경계를 만들 수 없다 은닉층의 개수가 너무 많아 역전파 과정에서 발생하는 문제 기울기 소실 문제 Softmax() 각 범주에 속할 사후 확률을 제공하는 함수 홀드아웃방법 모형 평가 방법 중 주어진 데이터를 랜덤 하게 두 개의 데이터로 구분하여 사용하는 방법으로 주로 학습용과 시험용으로 분리하여 사용하는 방법 향상도곡선 분류 분석의 모형을 평가하는 방법으로 랜덤 모델과 비교하여 해당 모델의 성과가 얼마나 향상되었는지를 각 등급별로 파악하는 그래프 의사결정나..
분석 과제 발굴 방식 중 하향식 접근법 문제 발견 -> 문제 정의 -> 해결책 탐색 -> 데이터 분석 타당성 평가 빅데이터 분석 방법론의 분석 기획 단계 ①비즈니스 이해 및 범위 설정 ②프로젝트 정의 및 계획 수립 ③프로젝트 위험 계획 수립 분석 마스터플랜을 수립할 때 적용 범위 및 방식에 대한 고려요소 ①업무 내제화 적용 수준 ②분석 데이터 적용 수준 ③기술 적용 수준 마스터플랜 수립할 때 우선순위 고려요소 ①전략적 중요도 ②비즈니스 성과/ROI ③실행 용이성 비즈니스 모델 캔버스 업무 -> 제품 -> 고객 -> 규제&감사 -> 지원 인프라 빅데이터기획전문가 회사 내 기능 조직, 비즈니스 분석 또는 BI조직에 소속되어 있으면서 빅데이터 분석 전문 조직과 협력을 통하여 업무에 필요한 분석 모델이나 예측 ..
오늘은 간단하게 이번 2월 26일 시험인 ADsP 기출을 풀다가 틀린 문제를 제가 다시 보려고 작성하는 오답노트라고 할 수 있겠습니다. 시작해볼게요! 반정형데이터 내부에 메타 데이터 갖고 있음 메타 데이터 데이터에 관한 구조화된 데이터로, 다른 데이터를 설명해주는 데이터 데이터 매시업(Mashup) 기존에 풀기 어려웠던 문제 해결에 도움 CRM 단순한 정보의 수집에서 탈피, 분석 중심의 시스템 구축 지향 ERP 기업 전체를 경영자원의 효과적 이용이라는 관점에서 통합적으로 관리하고 경영의 효율화를 기하기 위한 시스템 플랫폼형 비즈니스 모델 상품, 서비스, 기술 등의 기반 위에 다른 이해관계자들이 보완적인 상품, 서비스, 기술을 제공하는 생태계 구축을 목표로 하는 비즈니스 모델 데이터 난수화 사생활 침해 막..
 [R] 토픽모델링
[R] 토픽모델링
안녕하세요. 오늘은 토픽모델링에 대해 알아볼게요. 우선 토픽모델링이란? 토픽 모델링(Topic Modeling)은 전체 내용물에서 일정한 패턴을 발견해 내는 알고리즘 기반 텍스트 마이닝(Text Mining)의 한 형태입니다. 위의 사진을 보면 노란색 박스에 분류된 그룹은 유전과 관련된 단어 핑크색 박스에 분류된 그룹은 생명 초록색 박스는 뇌과학, 하늘색 박스는 컴퓨터과학과 관련됐다고 유추할 수 있습니다! 그렇다면 우리는 R로 구현하여 위와 같이 만들어보겠습니다. 그중 LDA(Latent Dirichlet Allocation)를 활용해볼게요! # 패키지 설치 install.packages("topicmodels") install.packages("tidytext") install.packages("tid..
 [EDA] FA with R
[EDA] FA with R
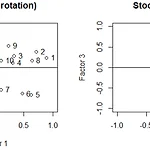
안녕하세요! 오늘은 Factor Analysis의 약자인 FA에 대해 알아보겠습니다. 파일은 저번이랑 똑같은 이 파일입니다. 만약 파일 정보가 필요하시다면 2022.02.06 - [분류 전체보기] - [EDA] PCA with R [EDA] PCA with R 오늘은 Principal Component Analysis 일명 PCA에 대해 간단한 예제를 R을 통해 알아보는 시간을 갖겠습니다! 그러기에 앞서 필요한 파일을 첨부하겠습니다. 위 데이터는 주식에 관한 10개 회사의 값입니 tnqkrdmssjan.tistory.com 여기서 확인해주세요! 그럼 시작하겠습니다. ### perfrom factor analysis with 3 factors but without any rotation kval>> Loa..
 [EDA] PCA with R
[EDA] PCA with R
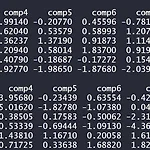
오늘은 Principal Component Analysis 일명 PCA에 대해 간단한 예제를 R을 통해 알아보는 시간을 갖겠습니다! 그러기에 앞서 필요한 파일을 첨부하겠습니다. 위 데이터는 주식에 관한 10개 회사의 값입니다. 그럼 시작해볼까요? rm(list=ls()) #할당변수 모두 제거 load("stockreturns.RData") #데이터 불러오기 ls() #변수 확인 >>> [1] "stocks" head(stocks) tail(stocks) str(stocks) #구조 파악 >>> 'data.frame':100 obs. of 10 variables: $ comp1 : num 0.44781 0.98811 0.87456 0.7144 0.00535 ... $ comp2 : num 0.0673 1...
 [EDA] SVD with R
[EDA] SVD with R
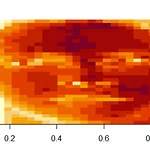
안녕하세요! 오늘은 Singular Value Decomposition의 약자인 SVD에 대해 R을 통해 알아보겠습니다. 우선 코딩에 필요한 파일을 올려놨습니다. 그럼 시작해볼게요! load("face.rda") #파일 불러오기 image(t(faceData)[, nrow(faceData):1]) svd1$d #singular value >>> [1] 1.977887e+01 1.513802e+01 1.213935e+01 8.427234e+00 6.200006e+00 [6] 4.936858e+00 4.402278e+00 3.967227e+00 3.743197e+00 3.017167e+00 [11] 2.967196e+00 2.406314e+00 1.899693e+00 1.555837e+00 1.492379e..
 [EDA] K-Means Clustering with R
[EDA] K-Means Clustering with R
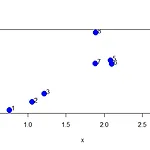
안녕하세요! 오늘은 EDA수업에서 배우는 또 다른 Clustering 기법인 k-means clustering을 R을 통해 알아보겠습니다. 간단한 좌표 설정 set.seed(1234) #rnorm으로 생성된 값 계속쓰기 위해 고정 x >> [1] 3 3 3 3 1 1 1 1 2 2 2 2 points(x, y, col = kmeansObj$cluster, pch = 19, cex = 2) image() 이용하기 par(mfrow=c(1,2)) #그래픽 1행 2열로 보이게 image(t(dataFrame)[, nrow(dataFrame):1], yaxt = "n", main = "Original Data") image(t(dataFrame)[, order(kmeansObj$cluster)], yaxt = ..
 [수리통계학] Continuous Distributions
[수리통계학] Continuous Distributions
안녕하세요! 오늘은 Discrete Distribution의 소개에 이어서 대표적인 Continuous Distribution을 알아보겠습니다. 1. Uniform Distribution : The random variable X has a uniform distribution. 2. Exponential Distribution : In Poisson process with mean number of changes λ in the unit interval, if the random variable X denote the waiting time until the first change occurs, then distribution of X is an exponential distribution. 3. Ga..
 [수리통계학] Discrete Distributions
[수리통계학] Discrete Distributions
안녕하세요! 오늘은 대표적인 이산형 분포의 종류를 나열해보겠습니다. 1. Discrete Uniform Distribution : When a pmf is constant on the space R of X; we say that the distribution is a discrete uniform abbreviated by DU. 2. Hypergeometric Distribution : Suppose there are N1 success objects and N2 failure objects in a collection N = N1 + N2 of similar objects. When n objects are selected from these N objects at random with withou..