
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 이것이 코딩테스트다
- 자격증
- 파이썬
- ADsP
- sklearn
- 데이터분석
- 데이터분석준전문가
- 이코테
- r
- 코딩테스트
- Python
- pandas
- 통계
- SQL
- 태블로
- scikit learn
- tableau
- SQLD
- 딥러닝
- 시각화
- 데이터 전처리
- 머신러닝
- pytorch
- 회귀분석
- Deep Learning Specialization
- IRIS
- 데이터 분석
- ML
- Google ML Bootcamp
- matplotlib
- Today
- Total
목록통계 (72)
함께하는 데이터 분석
 [Tableau] 파이차트 그리기
[Tableau] 파이차트 그리기
안녕하세요. 오늘은 태블로를 사용하여 파이 차트를 그려보겠습니다. 시작해볼게요. 기본 파이차트 이렇게 저번 시간에 한 것처럼 Expenses와 Region을 클릭하면 위와 같이 막대그래프가 그려집니다. 여기서 오른쪽 위의 표현방식에서 파이 차트 모양을 클릭하시면 이렇게 간단하게 파이 차트가 그려집니다. 이제 파이 차트의 크기를 화면에 맞춰보겠습니다. 위의 표준을 전체보기로 바꿔주시면 됩니다. 이제 각종 마크 레이블을 추가하겠습니다. 각종 마크 레이블 추가하기 Expenses를 레이블로 드래그를 하여 간단하게 마크 레이블을 달아주었습니다. 이번에는 지역 이름을 달아주겠습니다. Region을 레이블에 드래그해줬습니다. 지역이 위에 나오는 것이 보기 편하므로 뒤에서 한 번에 바꿔주겠습니다. 이번에는 Expen..
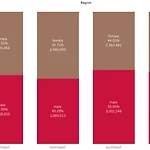 [Tableau] 누적 막대그래프
[Tableau] 누적 막대그래프
안녕하세요. 저번 포스트에서는 막대그래프를 알아봤습니다. 마지막에 누적 막대그래프를 그리긴 했는데 더 다양한 방식으로 누적 막대그래프를 그리고 해석하기 위해 따로 준비를 했습니다. 시작해볼게요. 기본 누적 막대그래프 저번 시간에도 이 정도까지는 그렸습니다. 보험 비용의 합계를 지역별로 나눠주고 추가로 성별로도 나눠준 모습입니다. 이때 범례가 아닌 누적 막대그래프에 성별을 마크 레이블로 표시해주겠습니다. 차원 마크레이블 표시 Sex를 빨간색으로 표시한 레이블에 드래그하면 위와 같이 성별도 마크 레이블로 추가되어 쉽게 구별할 수 있습니다. 이제 합계를 구성 비율로 표시해보겠습니다. 누적 막대그래프 구성 비율로 표시 마크 레이블에 있는 Expenses의 오른쪽 세모를 클릭한 다음 퀵 테이블 계산에서 구성비율을..
 [SQL] 단일 행 함수
[SQL] 단일 행 함수
오늘은 SQL을 통해 단일 행 함수에 대해 알아보겠습니다. 단일 행 함수는 숫자형, 문자형, 날짜형, 형 변환, 일반 함수로 나뉩니다. 표로 요약하여 보여드리겠습니다. 구분 함수 설명 숫자형 함수 abs(숫자) 절댓값 반환 round(숫자, n) 소수점 n자리까지 반올림 sqrt(숫자) 양의 제곱근 값 반환 문자형 함수 lower(문자) / upper(문자) 소문자 / 대문자 반환 left(문자, n) / right(문자, n) 왼쪽 / 오른쪽 n만큼 반환 length(문자) 문자수 반환 날짜형 함수 year / month / day 연 / 월 / 일 반환 date_add(날짜, interval) 날짜에 interval만큼 반환 datediff(날짜a, 날짜b) 날짜a - 날짜b 일수 반환 형변환 함수 ..
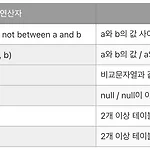 [SQL] 특수 연산자, 집합 연산자
[SQL] 특수 연산자, 집합 연산자
이번에는 SQL을 통해 특수 연산자와 집합 연산자를 알아보겠습니다. 연산자에 대한 설명을 표로 보여드리겠습니다. 구분 연산자 설명 특수 연산자 between a and b / not between a and b a와 b의 값 사이 / a와 b의 값 사이가 아님 in (a, b) / not in (a, b) a와 b의 값 / a와 b의 값이 아님 like '비교문자열' 비교문자열과 같음 is null / is not null NULL / NULL이 아님 집합 연산자 union 2개 이상 테이블의 중복된 행 제거하여 집합 union all 2개 이상 테이블의 중복된 행 제거없이 집합 그럼 이제 SQL workbench를 통해 살펴보겠습니다. 데이터 베이스 /* 데이터베이스 da 사용 */ use da; 이전..
 [SQL] 비교 연산자, 논리 연산자
[SQL] 비교 연산자, 논리 연산자
오늘은 SQL을 통해 비교 연산자와 논리 연산자를 알아보겠습니다. 우선 연산자에 대해 표로 설명드리겠습니다. 구분 연산자 설명 비교 연산자 = ~와 같다 ~와 같지 않다 >= ~보다 크거나 같다 ~보다 크다 = : 크거나 같음 */ select * from insurance where children >= 2; >= 연산자를 이용하여 2보다 크거나 같은 데이터만 불러왔습니다. /* 연산자를 이용하여 2보다 큰 데이터만 불러왔습니다. >= 와 다르게 children이 2인 데이터가 안 보이는 것을 확인할 수 있죠. /* < : 작음 */ select * from insurance where children < 2; < 연산자를 이용하여 2보다 작은 데이터만 불러왔습니다.
 [SQL] 테이블 결합 - JOIN
[SQL] 테이블 결합 - JOIN
오늘은 여러 개의 테이블을 결합하는 데 사용하는 Join을 알아보겠습니다. 두 개 혹은 그 이상의 테이블이 있을 때 하나의 테이블로 합쳐서 보고 싶을 때 사용합니다. column의 공통된 데이터 값을 기준으로 테이블을 결합합니다. SQL에서 Join은 크게 3가지 종류가 있습니다. Inner Join : 테이블의 공통되는 값에 매칭 되는 데이터만 결합 Left Join : 왼쪽 테이블을 기준으로 테이블의 공통 값이 매칭 되고 왼쪽 테이블에 매칭 되지 않는 오른쪽 테이블의 데이터는 NULL처리 Right Join : 오른쪽 테이블을 기준으로 테이블의 공통 값이 매칭 되고 오른쪽 테이블에 매칭 되지 않는 왼쪽 테이블의 데이터는 NULL처리 그럼 workbench를 통해 자세히 살펴볼까요? 데이터 베이스 사용..
 [SQL] 데이터 조회 - SELECT
[SQL] 데이터 조회 - SELECT
오늘은 데이터를 조회하는 데 사용하는 Select를 조금 더 자세히 알아보겠습니다. Select는 앞에 SQL 명령어 중 데이터 조작어에서 살짝 다뤘습니다. 뒤에서 자세히 다루는 이유는 앞으로 많이 사용하기 때문인데요. 데이터를 분석할 때 Select는 여러 가지 절들과 함께 사용합니다. 대표적으로 from, where, group by, having, order by가 있습니다. 오늘 사용할 데이터는 insurance 데이터입니다. 앞서 R을 통한 회귀분석에서도 이 데이터를 사용했죠. 이제 Workbench에서 살펴보겠습니다. 데이터 베이스 사용 /* 데이터베이스 da 사용 */ use da; 데이터 베이스 da를 사용하겠습니다. 데이터 불러오기 왼쪽의 da 데이터베이스에 마우스 오른쪽을 클릭하면 Ta..
 [SQL] 트랜젝션 제어어(TCL)
[SQL] 트랜젝션 제어어(TCL)
이번에는 SQL 명령어 4가지 중 마지막인 트랜젝션 제어어(TCL)에 대해 알아보겠습니다. 트랜젝션 제어어는 데이터 조작어(DML) 명령어를 실행, 취소, 임시 저장할 때 사용하는 명령어입니다. Workbench를 통해 알아보겠습니다. 테이블 생성 /* 테이블 생성 */ create table 인적사항 ( 인덱스 int primary key, 이름 varchar(10), 생년월일 date not null, 성별 varchar(2) ); 전에 만들었던 인적사항 테이블을 그대로 가져왔습니다. 트랜젝션을 시작해보겠습니다. 트랜젝션 시작 /* 트랜젝션 시작 */ begin; 항상 트랜젝션을 시작할 때 begin; 을 실행해줘야 합니다. 이제 트랜젝션을 통해 취소를 하는 방법을 알아보겠습니다 취소(rollback..
 [SQL] 데이터 제어어(DCL)
[SQL] 데이터 제어어(DCL)
오늘은 SQL의 명령어 중 하나인 데이터 제어어(DCL)에 대해 알아보겠습니다. 데이터 제어어는 데이터 접근 권한을 부여하거나 제거할 때 사용하는 명령어입니다. Workbench를 통해 살펴보겠습니다. MySQL 데이터베이스 사용 /* MySQL 데이터베이스 사용 */ use mysql; 사용자 확인 /* 사용자 확인 */ select * from user; 이렇게 기존의 4개의 localhost가 있습니다. 여기에 제가 사용자를 추가해보도록 하겠습니다. 사용자 추가 /* 사용자 아이디 및 비밀번호 생성 */ create user 'JH' @localhost identified by '1234'; create user로 JH 사용자를 추가하고 identified by로 비밀번호를 1234로 설정했습니다...
 [SQL] 데이터 조작어(DML)
[SQL] 데이터 조작어(DML)
오늘은 SQL 명령어 4가지 중 하나인 데이터 조작어(DML)에 대해 알아보겠습니다. 저번 시간에 데이터 정의어를 통해 테이블을 생성, 변경, 삭제를 해봤는데요. 데이터 조작어는 데이터를 삽입, 조회, 수정, 삭제할 때 사용하는 명령어입니다. 코드를 통해 알아보겠습니다. 데이터 베이스 사용 /* 데이터베이스 DA 사용 */ use da; 저번 데이터 정의어를 공부할 때 만들어놓은 데이터 베이스 da를 사용하겠습니다. 테이블 생성 /* 테이블 생성 */ create table 인적사항 ( 인덱스 int primary key, 이름 varchar(10), 생년월일 date not null, 성별 varchar(2) ); 테이블도 저번 시간에 만들어본 인적사항 테이블을 그대로 사용하겠습니다. 테이블 데이터 삽..