| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터 분석
- SQL
- IRIS
- 코딩테스트
- r
- 자격증
- Deep Learning Specialization
- 시각화
- matplotlib
- Google ML Bootcamp
- pytorch
- ADsP
- scikit learn
- sklearn
- SQLD
- 이코테
- 태블로
- 딥러닝
- 통계
- 데이터분석
- 데이터 전처리
- ML
- 회귀분석
- tableau
- pandas
- 파이썬
- 이것이 코딩테스트다
- 데이터분석준전문가
- 머신러닝
- Python
- Today
- Total
목록eda (5)
함께하는 데이터 분석
 [EDA] FA with R
[EDA] FA with R
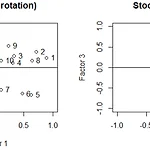
안녕하세요! 오늘은 Factor Analysis의 약자인 FA에 대해 알아보겠습니다. 파일은 저번이랑 똑같은 이 파일입니다. 만약 파일 정보가 필요하시다면 2022.02.06 - [분류 전체보기] - [EDA] PCA with R [EDA] PCA with R 오늘은 Principal Component Analysis 일명 PCA에 대해 간단한 예제를 R을 통해 알아보는 시간을 갖겠습니다! 그러기에 앞서 필요한 파일을 첨부하겠습니다. 위 데이터는 주식에 관한 10개 회사의 값입니 tnqkrdmssjan.tistory.com 여기서 확인해주세요! 그럼 시작하겠습니다. ### perfrom factor analysis with 3 factors but without any rotation kval>> Loa..
 [EDA] PCA with R
[EDA] PCA with R
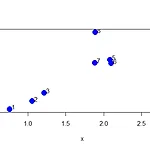
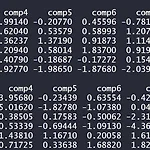
오늘은 Principal Component Analysis 일명 PCA에 대해 간단한 예제를 R을 통해 알아보는 시간을 갖겠습니다! 그러기에 앞서 필요한 파일을 첨부하겠습니다. 위 데이터는 주식에 관한 10개 회사의 값입니다. 그럼 시작해볼까요? rm(list=ls()) #할당변수 모두 제거 load("stockreturns.RData") #데이터 불러오기 ls() #변수 확인 >>> [1] "stocks" head(stocks) tail(stocks) str(stocks) #구조 파악 >>> 'data.frame':100 obs. of 10 variables: $ comp1 : num 0.44781 0.98811 0.87456 0.7144 0.00535 ... $ comp2 : num 0.0673 1...
 [EDA] SVD with R
[EDA] SVD with R
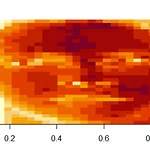
안녕하세요! 오늘은 Singular Value Decomposition의 약자인 SVD에 대해 R을 통해 알아보겠습니다. 우선 코딩에 필요한 파일을 올려놨습니다. 그럼 시작해볼게요! load("face.rda") #파일 불러오기 image(t(faceData)[, nrow(faceData):1]) svd1$d #singular value >>> [1] 1.977887e+01 1.513802e+01 1.213935e+01 8.427234e+00 6.200006e+00 [6] 4.936858e+00 4.402278e+00 3.967227e+00 3.743197e+00 3.017167e+00 [11] 2.967196e+00 2.406314e+00 1.899693e+00 1.555837e+00 1.492379e..
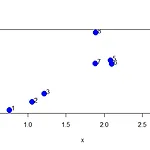 [EDA] K-Means Clustering with R
[EDA] K-Means Clustering with R
안녕하세요! 오늘은 EDA수업에서 배우는 또 다른 Clustering 기법인 k-means clustering을 R을 통해 알아보겠습니다. 간단한 좌표 설정 set.seed(1234) #rnorm으로 생성된 값 계속쓰기 위해 고정 x >> [1] 3 3 3 3 1 1 1 1 2 2 2 2 points(x, y, col = kmeansObj$cluster, pch = 19, cex = 2) image() 이용하기 par(mfrow=c(1,2)) #그래픽 1행 2열로 보이게 image(t(dataFrame)[, nrow(dataFrame):1], yaxt = "n", main = "Original Data") image(t(dataFrame)[, order(kmeansObj$cluster)], yaxt = ..