
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 자격증
- 이것이 코딩테스트다
- IRIS
- ML
- sklearn
- pytorch
- 딥러닝
- Deep Learning Specialization
- 태블로
- 통계
- Google ML Bootcamp
- 시각화
- tableau
- 데이터 전처리
- 데이터 분석
- 코딩테스트
- r
- 데이터분석
- Python
- matplotlib
- SQL
- 머신러닝
- pandas
- scikit learn
- 회귀분석
- ADsP
- 파이썬
- 데이터분석준전문가
- 이코테
- SQLD
- Today
- Total
목록데이터분석 공부 (64)
함께하는 데이터 분석
 [Pytorch] 순환 신경망 모델 학습
[Pytorch] 순환 신경망 모델 학습
모델 구현 import torch import torch.nn as nn import torch.optim as optim import numpy as np from tqdm.notebook import tqdm n_hidden = 35 # 순환 신경망의 노드 수 lr = 0.01 epochs = 1000 string = "hello pytorch. how long can a rnn cell remember? show me your limit!" chars = "abcdefghijklmnopqrstuvwxyz ?!.,:;01" char_list = [i for i in chars] n_letters = len(char_list) 예시에서 사용할 문장은 'hello pytorch. how long can ..
 [RNN] 순환 신경망
[RNN] 순환 신경망
순환 신경망의 발달 과정 순환 신경망(RNN)은 합성곱 신경망보다 먼저 나왔음 위키피디아에 따르면 1982년 존 홉필드가 순환 신경망의 기본적인 형태를 대중화했다고 알려져 있지만, 해당 아이디어가 이때 처음 나온 것은 아니고 이전에도 언급된 적이 있음 이때 만들어진 순환 신경망이 오늘날의 순환 신경망의 형태로 오기까지는 꽤 많은 시간이 걸렸는데, 발전된 연산 능력과 데이터의 증가로 인해 성과를 보일 수 있게 된 것 특히 발전 과정에서 나온 LSTM(long short-term memory)과 GRU(gated recurrent unit)같은 변형 모델들은 오늘날에도 많이 사용되고 있음 순환 신경망이 왜 필요한지를 살펴보면 TRIANGLE과 INTEGRAL이라는 글자는 같은 알파벳들의 나열이지만 순서가 다..
 [Pytorch] 인공 신경망 모델 학습
[Pytorch] 인공 신경망 모델 학습
모델 구현 import torch import torch.nn as nn import torch.optim as optim import torch.nn.init as init from tqdm.notebook import tqdm import matplotlib.pyplot as plt torch.nn에는 신경망 모델들이 포함 torch.optim에는 경사 하강법 알고리즘이 들어있음 torch.nn.init에는 텐서에 초깃값을 주기 위해 필요한 함수들이 있음 tqdm 라이브러리를 사용하여 상태진행률을 확인할 수 있음 num_data = 1000 num_epoch = 10000 noise = init.normal_(torch.FloatTensor(num_data,1), std=1) x = init.unif..
 [Python] 파이토치(Pytorch) 설치하기
[Python] 파이토치(Pytorch) 설치하기
Pytorch란? 파이토치는 2017년 초에 공개된 딥러닝 프레임워크로 GPU를 활용하여 인공 신경망 모델을 만들고 학습시킬 수 있게 도와줌 Numpy라이브러리에 비해 계산이 간단하고 병렬 연산에서 GPU를 사용하므로 CPU보다 속도면에서 월등히 빠름 유명한 딥러닝 프레임워크인 텐서플로(tensorflow)는 'Define and Run' 방식으로 연산 그래프를 먼저 만들고 실제 연산할 때 값을 전달하여 결과를 얻고 파이토치(Pytorch)는 'Define by Run' 방식으로 연산 그래프를 정의하는 것과 동시에 값도 초기화되어 연산이 이루어지고 연산 속도도 빠르고, 적어도 밀리지는 않음 Pytorch 설치하기 https://pytorch.org/ PyTorch An open source machine..
 [Python] excel, csv, tsv 불러오기 및 저장하기
[Python] excel, csv, tsv 불러오기 및 저장하기
csv와 tsv의 차이 csv : 콤마로 텍스트를 구분 tsv : 탭으로 텍스트를 구분 종류 excel csv(comma separated value) tsv(tab separated value) seperator , \t 불러오기 read_excel read_csv(sep=',') read_csv(sep='\t') excel 파일 불러오기 import pandas as pd # 판다스 라이브러리 불러오기 pd.read_excel('저장된 경로/저장된 파일명.xlsx') csv 파일 불러오기 import pandas as pd # 판다스 라이브러리 불러오기 pd.read_csv('저장된 경로/저장된 파일명.csv', sep=',') # separator 생략 가능 pd.read_csv('저장된 경로/저장..
 [Scikit Learn] PCA
[Scikit Learn] PCA
주성분 분석(Principal Component Analysis) 차원을 축소하는 알고리즘 중 가장 인기 있는 알고리즘 사이킷런 import numpy as np np.random.seed(4) m = 60 w1, w2 = 0.1, 0.3 noise = 0.1 angles = np.random.rand(m) * 3 * np.pi / 2 - 0.5 X = np.empty((m, 3)) X[:, 0] = np.cos(angles) + np.sin(angles)/2 + noise * np.random.randn(m) / 2 X[:, 1] = np.sin(angles) * 0.7 + noise * np.random.randn(m) / 2 X[:, 2] = X[:, 0] * w1 + X[:, 1] * w2 + n..
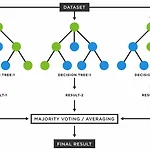 [Scikit Learn] Random Forest
[Scikit Learn] Random Forest
랜덤 포레스트(Random Forest) 배깅 방식을 적용한 의사결정 나무(Decision Tree)의 앙상블 따라서 사이킷런의 BaggingClassifier에 DecisionTreeClassifier를 넣어 만들거나 RandomForestClassifier를 사용 사이킷런 from sklearn.model_selection import train_test_split from sklearn.datasets import make_moons X, y = make_moons(n_samples=500, noise=0.3, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) 사이킷런의 moons 데이..
 [Python] 시각화 / graphviz
[Python] 시각화 / graphviz
파이썬에서 의사결정 나무를 시각화할 때 graphviz 라이브러리를 import 해야 합니다. 이 라이브러리는 추가로 설치해야 하는데 윈도우를 사용하는 사람들의 설치법은 구글링을 하면 많지만 맥을 사용하는 사람은 그 방법으로 했을 때 오류가 많고 안 되는 경우가 많습니다. 그래서 제가 오랫동안 여러 가지 방법을 시도해보고 성공한 아나콘다에서의 설치방법을 알려드리겠습니다. 1. Homebrew https://brew.sh/index_ko Homebrew The Missing Package Manager for macOS (or Linux). brew.sh Homebrew는 mac os에서 라이브러리 설치를 도와줍니다. Spotlight에서 터미널을 검색하여 실행한 후 /bin/bash -c "$(curl ..
 [Ensemble] 머신러닝 앙상블 기법
[Ensemble] 머신러닝 앙상블 기법
오늘은 머신러닝에서 자주 등장하는 앙상블 기법에 대해 알아볼게요! 우선 앙상블(Ensemble)이란 여러 개의 분류기를 생성하여 예측값을 종합하여 보다 정확한 예측값을 구하고 각각의 분류기를 사용했을 때의 단점을 보완해주는 기법입니다. 앙상블 기법에는 대표적으로 Voting, Bagging, Boosting이 있습니다. 이제 각각의 기법을 간단하게 살펴보겠습니다! Voting 보팅에는 Hard Voting과 Soft Voting이 있습니다. Hard Voting은 weak learner들의 예측값을 다수결의 원칙을 사용하여 나타내는 것입니다. 위의 사진을 보면 1을 예측한 분류기가 3개, 2를 예측한 분류기가 1개 이므로 다수결의 원칙에 따라 1로 예측하는 것입니다. 최빈값으로 결정한다고 할 수 있죠. ..
 [Scikit Learn] One-Hot Encoding
[Scikit Learn] One-Hot Encoding
안녕하세요. 머신러닝을 돌리기 전 전처리 작업 중 하나인 인코딩에 대해 살펴볼게요. 전 포스트에서 말씀드렸기에 간단하게 설명한다면 인코딩은 문자형 변수를 수치형 변수로 변환해주는 것입니다. 저번 포스팅에서는 Label Encoding을 알아봤고 이번에는 One-Hot Encoding을 살펴볼게요. One-Hot Encoding 머신러닝을 공부하신 분들이라면 한 번씩은 들어보셨을 One-Hot Encoding입니다. One-Hot Encoding은 말 그대로 하나만 Hot하고 나머지는 Cold 한다는 뜻입니다. 새로운 칼럼을 추가하여 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시합니다. 이제 Python을 통해 One-Hot Encoding을 진행해보겠습니다. 라이브러리 불러오기 import ..