
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- r
- SQL
- 이코테
- SQLD
- ML
- 코딩테스트
- 딥러닝
- 머신러닝
- 데이터분석
- 데이터 전처리
- 파이썬
- scikit learn
- IRIS
- pytorch
- tableau
- matplotlib
- ADsP
- 데이터분석준전문가
- sklearn
- 시각화
- Deep Learning Specialization
- 회귀분석
- 자격증
- Python
- 통계
- 이것이 코딩테스트다
- Google ML Bootcamp
- pandas
- 데이터 분석
- 태블로
- Today
- Total
목록통계 (72)
함께하는 데이터 분석
 [수리통계학] Continuous Distributions
[수리통계학] Continuous Distributions
안녕하세요! 오늘은 Discrete Distribution의 소개에 이어서 대표적인 Continuous Distribution을 알아보겠습니다. 1. Uniform Distribution : The random variable X has a uniform distribution. 2. Exponential Distribution : In Poisson process with mean number of changes λ in the unit interval, if the random variable X denote the waiting time until the first change occurs, then distribution of X is an exponential distribution. 3. Ga..
 [수리통계학] Discrete Distributions
[수리통계학] Discrete Distributions
안녕하세요! 오늘은 대표적인 이산형 분포의 종류를 나열해보겠습니다. 1. Discrete Uniform Distribution : When a pmf is constant on the space R of X; we say that the distribution is a discrete uniform abbreviated by DU. 2. Hypergeometric Distribution : Suppose there are N1 success objects and N2 failure objects in a collection N = N1 + N2 of similar objects. When n objects are selected from these N objects at random with withou..
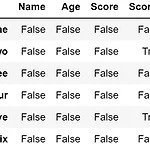 [Python] Pandas - ②
[Python] Pandas - ②
저번에 다 작성하지 못했던 Pandas 라이브러리를 마무리하려고 합니다! 그럼 시작해볼까요? 5-1. 결측치 여부 확인 df2.isnull() df2.isnull().sum() # 각 열마다 결측치 개수 출력 >>> Name 0 Age 0 Score 0 Score2 2 dtype: int64 5-2. 결측치가 존재하는 행 삭제 df2.dropna(how = 'any') # how = 'all' : 행의 모든 값이 NaN인 경우 삭제 5-3. 결측치 대체 df2.fillna(value = 50.0) # 기본적으로 저장 X df2['Score2'].fillna({'two' : 68.0, 'five': 80.0}, inplace = True) # inplace = True : 저장 df2 6-1. 기술 통계 ..
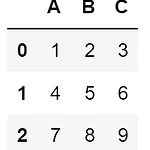 [Python] Pandas - ①
[Python] Pandas - ①
오늘은 말씀드린 대로 NumPy에 이어서 Pandas 라이브러리에 대해 알아보겠습니다! Pandas 라이브러리는 대표적인 데이터 분석 라이브러리이며 행과 열로 이루어진 데이터 객체를 만들고 다룰 수 있어 안정적으로 대용량의 데이터를 처리하는 데 매우 편리하다는 장점이 있습니다. 이번에도 마찬가지로 주피터 노트북을 이용했으며 이용하고 싶으시다면 2022.01.22 - [데이터 분석 공부하기/Python] - [Python] Jupyter Notebook 설치 및 실행 [Python] Jupyter Notebook 설치 및 실행 오늘은 간단하게 Anaconda를 설치하여 주피터 노트북을 실행시키는 방법을 알아볼게요! 우선 아나콘다는 수학과 과학 분야에서 사용되는 여러 패키지들을 묶어 놓은 파이썬 배포판이고 ..
안녕하세요! 오늘은 파이썬에서 다차원 배열을 효과적으로 처리할 수 있고 수학 및 과학 연산에 유용한 NumPy 라이브러리에 대해 알아보려고 합니다. 우선 코딩은 주피터 노트북을 활용했습니다! 만약 주피터 노트북을 이용하고 싶으시다면 2022.01.22 - [데이터 분석 공부하기/Python] - [Python] Jupyter Notebook 설치 및 실행 [Python] Jupyter Notebook 설치 및 실행 오늘은 간단하게 Anaconda를 설치하여 주피터 노트북을 실행시키는 방법을 알아볼게요! 우선 아나콘다는 수학과 과학 분야에서 사용되는 여러 패키지들을 묶어 놓은 파이썬 배포판이고 대표적으 tnqkrdmssjan.tistory.com ^^^^ 여기를 눌러주시면 됩니다! 그럼 시작해볼게요~ 1...
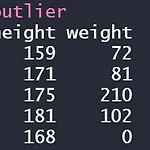 [R] 이상치(outlier)와 결측치(missing value) 처리하기
[R] 이상치(outlier)와 결측치(missing value) 처리하기
안녕하세요! 오늘은 데이터를 받아보면 이상치와 결측치가 종종 존재하는 경우를 볼 수 있는데요,, 이때 어떻게 처리해야 하는지를 알려드리겠습니다! 그럼 시작하겠습니다. 이상치(outlier) 란? - 통계적 자료 분석의 결과를 왜곡시키거나, 자료 분석의 적절성을 위협하는 변숫값 # 이상치(outlier) 정제하기 - NA 처리하기 outlier >> 85 만약 결측치 제외한 평균값만 구하고 싶다면? mean(outlier$weight, na.rm=T) #결측치 제외하는 함수 쓰고 평균 >>> 85 all.equal(mean(new_outlier$weight), mean(outlier$weight, na.rm=T)) #같은지 확인 >>> True 2. 결측치 대체하기(평균, 최빈값 등등) #결측치 대체하기 ..
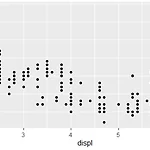 [R] ggplot2 패키지로 그래프 그리기
[R] ggplot2 패키지로 그래프 그리기
안녕하세요! 오늘은 R의 패키지인 ggplot2를 이용하여 여러 가지 그래프를 그리는 방법을 알려드리겠습니다! 그럼 시작하겠습니다 함수 내용 geom_point() 산점도 geom_col() 막대그래프 - 요약표(평균) geom_bar() 막대그래프 - 원자료(빈도) geom_line() 선(시계열) 그래프 geom_boxplot() 상자 그림 ggplot2 설치 및 실행 install.packages("ggplot2") library(ggplot2) #ggplot2 실행 library(dplyr) #dplyr 실행 산점도 그리기 # 산점도 그리기 ggplot(data = mpg, aes(x = displ, y= hwy)) + geom_point() 이때 x축과 y축을 조절해서 보고 싶다면? # 축 범위..
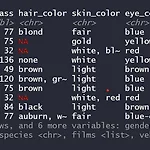 [R] dplyr 패키지 맛보기
[R] dplyr 패키지 맛보기
오늘은 통계 분석할 때 알아두면 편한 dplyr 패키지를 공부할 거예요! 이때 dplyr을 사용하지 않고 결과를 도출하는 코드와 dplyr을 사용하여 결과를 도출하는 2가지 방법 모두 코드를 올려놓을 테니 비교해 보는 재미도 있을 것 같아요!! 그럼 시작해볼까요? dplyr 함수 기능 %>% 함수 연결 filter() 행 추출 select() 열(변수) 추출 arrange() 정렬 mutate() 변수 추가 summarise() 통계량 산출 group_by() 집단별로 나누기 dplyr을 설치하는 방법 # dplyr 설치 install.packages("dplyr") 만약 설치 오류가 난다면 Rstudio를 실행할 때 관리자 권한으로 실행을 누르세요 dplyr을 실행하는 방법 # dplyr 실행 libr..
엔터티의 개념 명사, 업무상 관리 필요한 관심사, 저장이 되기 위한 어떤 것(Thing) 엔터티의 특징 업무에서 필요하고 관리하고자 하는 정보 유일한 식별자에 의해 식별이 가능해야 함 인스턴스 2개 이상의 집합 업무 프로세스에 의해 이용되어야 함 반드시 속성이 있어야 함(주식별자만 존재하고 일반속성 없어도 적절하지 않음, 관계 엔터티 예외) 다른 엔터티와의 관계가 최소 1개 이상 존재(통계성, 코드성, 내부필요 엔터티는 예외) 엔터티의 분류 유무형에 따른 분류 유형엔터티 : ex)사원, 물품, 강사 개념엔터티 : ex)조직, 보험상품 사건엔터티 : ex)주문, 청구, 미납 발생시점에 따른 분류 기본엔터티 : ex)사원, 부서, 고객, 상품, 자재 중심엔터티 : ex)계약, 사고, 예금원장, 청구, 주문 ..
SQLD의 암기 부분이라고 할 수 있는 1과목을 총 3~4번에 걸쳐 핵심만 요약해 보는 시간을 가져보겠습니다! 1과목에서 고득점을 받는 것이 SQLD자격증을 취득하는 것의 핵심인데요 지금 시작하겠습니다. 1장 데이터 모델링의 이해 모델링 일정한 표기법에 의해 규칙을 가지고 표기하는 것 모델링의 특징 3가지 추상화 : 현실세계 일정한 형식에 맞추어 표현 단순화 : 복잡한 현실세계 약속된 규약에 의해 제한된 표기법/언어로 표현 쉽게 이해 명확화 : 누구나 이해하기 쉽게 대상의 애매모호함 제거 정확하게 현상을 기술 정보시스템 구축에서 모델링 활용 계획/분석/설계 할 때 업무를 분석하고 설계하는데 이용 구축/운영 단계에서는 변경과 관리의 목적으로 이용 모델링의 관점 3가지 데이터 관점(Data, What) : ..